|
MAIN PAGE
> Back to contents
Historical informatics
Reference:
Galushko I.N.
The use of topic modeling to optimize the process of searching for relevant historical documents (on the example of the stock exchange press of the early 20th century)
// Historical informatics.
2023. № 2.
P. 129-144.
DOI: 10.7256/2585-7797.2023.2.43466 EDN: SKBPNS URL: https://en.nbpublish.com/library_read_article.php?id=43466
The use of topic modeling to optimize the process of searching for relevant historical documents (on the example of the stock exchange press of the early 20th century)
Galushko Il'ya Nikolaevich
Graduate Student, Historical Information Science Department, History Faculty, Lomonosov Moscow State University
119234, Russia, g. Moscow, ul. Lomonosovskii Prospekt, 27, korp.4

|
i.galushko15@gmail.com
|
|
 |
Other publications by this author
|
|
|
DOI: 10.7256/2585-7797.2023.2.43466
EDN: SKBPNS
Received:
30-06-2023
Published:
14-07-2023
Abstract:
The key task of the presented article is to test how we can analyze the information potential of a historical sources collection by using thematic modeling. Some modern collections of digitized historical materials number tens of thousands of documents, and at the level of an individual researcher, it is difficult to cover available funds. Following a number of researchers, we suggest that thematic modeling can become a convenient tool for preliminary assessment of the content of a collection of historical documents; can become a tool for selecting only those documents that contain information relevant to the research tasks. In our case, the Birzhevye Vedomosti newspaper was chosen as one of the main collection of historical documents. At this stage, we can confirm that in our study, the use of topic modeling proved to be a productive solution for optimizing the process of searching for historical documents in a large collection of digitized historical materials. At the same time, it should be emphasized that in our work topic modeling was used exclusively as an applied tool for primary assessment of the information potential of a documents collection through the analysis of selected topics. Our experience has shown that, at least for Birzhevye Vedomosti, topic modeling with LDA does not allow us to draw conclusions from the standpoint of our content analysis methodology. The data of our models are too fragmentary, it can only be used for the initial assessment of the topics describing the information contained in the source.
Keywords:
topic modeling, Latent Dirichlet allocation, Birzhevye vedomosti, behavioral finance, Natural language processing, recognition of historical sources, historical newspapers, searching for historical documents, machine learning, stock market
This article is automatically translated.
You can find original text of the article here.
The key objective of the presented article is to test the methodology for analyzing the information potential of a collection of historical sources using thematic modeling. Some modern collections of digitized historical materials number tens of thousands of documents (as, for example, the "Electronic Library of Historical Documents" created by the Russian Historical Society (RIO) contains 294 thousand recognized historical documents [1] – and at the level of an individual researcher, it is difficult to cover all available heritage. Following a number of researchers [2], we assume that thematic modeling can become a convenient tool for preliminary assessment of the content of a collection of historical documents; a tool for selecting only those documents that contain information relevant to the research tasks set. Our research, for which the methodology described in the article was developed, is devoted to the study of the profitability of securities on the St. Petersburg Stock Exchange at the beginning of the XX century from the perspective of behavioral finance. We were interested in the principles of investment evaluation of public companies – how acceptable or insufficient levels of capitalization were determined; how securities were determined that were a good choice for placing capital, how widely these methods (if they existed) were used in the practice of exchange trading. The newspaper "Birzhevye Vedomosti" was chosen as one of the main sources, in the daily issues of which there was an exchange column, where the chronicler's comment was printed, which described the mood of the bidders and often provided a detailed analysis of the current situation in the economy of the Russian Empire. Analytical notes on the profitability of securities are often found in the columns of the "Exchange Statements": at what percentage the next issue of government debt securities is placed; at what level relative to the nominal value these securities are traded; whether the proposed percentage corresponds to the current statistics of the money market and how to explain the exchange rate dynamics of recent days. For the study, it was decided to collect a collection of such notes in order to identify stable analytical patterns characteristic of the stock exchange press in matters related to the profitability of securities. We used the materials of the digitized set of "Stock Exchange Statements" from the website of the Russian National Library (447 issues for 1905 and 1913, morning and evening issues). As part of a general study of the profitability of securities on the stock market of the Russian Empire, we were interested in a limited set of problems related to the behavioral and institutional aspects of the functioning of the stock market of the Russian Empire. On the contrary, the content of the "Exchange Statements" is diverse. And, except for the column of the stock chronicler, there are numbers that are completely devoid of the information we need. The content of such issues is filled with military news, theatrical and literary reviews, economic arguments of a non-exchange nature and other similar broad-profile articles (see Figures 1 and 2). And in this context, it is logical to turn to the possibilities of thematic modeling as an applied tool for automatic search of those numbers (pages) from our collection of digitized newspaper materials that contain information related to the functioning of the securities market. 
Figure 1. An example of the organization of the page of the number of "Exchange statements". 
Figure 2. Example of the text you are looking for. The "Lucky Girl" column. A story about how a certain woman found a bundle of shares in a store that banker Borisov had lost (Issue No. 13621 of June 28 (July 11)). * * * Thematic modeling is a method of machine learning without a teacher, used to determine the main topics of a collection of documents (or the topics of proposals of one document, which is considered in this case as a set of proposals) based on the allocation of topics (for the difference between the concepts of "topic" and "topic", see Appendix 1). As a rule, a topic is a probability-weighted list of words that together express the general content of the intended topic [2]. The higher the coefficient of a word, the more importance the model attaches to this word when forming a topic. So, Table 2 shows an example of two topics defined by our model for the third page of the issue of the "Stock Exchange Statements" dated April 29, 1913 (No. 13521): Table 1. Examples of two topics defined by the model, represented by a set of keywords and their probabilities (see Appendix 2.1) | Topics | | (1, '0.023*"warehouse" + 0.021*"action" + 0.016*"enterprise" + 0.012*"company" + 0.012*"steamship" + 0.012*"partnership" + 0.012*"transport" + 0.012*"fear" + 0.012*"iron" + 0.007*"balance"') | | (2, '0.015*"city" + 0.013*"paper" + 0.012*"loan" + 0.011*"road" + 0.007*"capital" + 0.007*"bond" + 0.007*"company" + 0.007*"share" + 0.006*"special" + 0.006*"have"') |
One of the most popular thematic modeling methods currently used is the latent Dirichlet distribution (LDA), which is a "generative probabilistic model for collections of discrete data, such as text corpora" [3]. This method is used within Digital Humanities to extract topics from a set of texts [4]. In this model, the document (in our case, a separate page of the newspaper issue of the Stock Exchange) is a mixture of topics, and the topic is a probability distribution according to the dictionary. A dictionary is understood as a list of all the words of the studied collection of documents – it is the dictionary that sets the word space in which the documents need to be distributed in such a way as to form the number of topics set by the researcher. An important feature of LDA is a predetermined number of topics, which is set before the start of training. A convenient function of LDA models is to set weights equal to 0.001 for words defining redundant topics. That is, if the researcher initially set the search for 5 topics for the model, and according to the results of thematic modeling for three topics, the model set different word weights varying in boundaries, for example, from 0.005 to 0.0021, and for the other two topics – the weight of 0.001 for all words – it means that LDA cannot distribute the text with the given settings more than 3 topics. In the course of our experiments, we found that a threshold of 5 topics is sufficient to solve our research problems. The creation of a dictionary can be supplemented by the use of various methods of text preprocessing. In our work, the lemmatization method, classic for computational linguistics, was used – bringing all words to the basic form. Another widely used method of preprocessing involves searching and adding to the dictionary of the bigram model – words with a double basis, distinguished in the text by the frequency of joint occurrence (for example, "joint-stock capital", "state rent"). We tested this approach initially when we planned to create an LDA model of the entire existing collection. With this approach, an entire issue of an exchange newspaper is considered as one document. However, the results turned out to be extremely impractical – due to the too wide spread of topics per issue of the newspaper, we were unable to create interpretable models. Adding filters (TF-IDF (see Appendix 1), changing the training parameters (for example, the size of the batch portion of data for the training iteration), increasing the number of topics (different options ranging from 5 to 30 topics) – could not improve the situation. Then we decided to create LDA models for individual issues of the newspaper, considering them as a collection of proposals. The results have improved, but still remain insufficient to use thematic modeling as a stable search algorithm. The last and most productive option turned out to be the construction of an LDA for each individual page in our collection of "Exchange Statements". This approach allowed us to create an algorithm for selecting materials relevant for research based on thematic modeling, but due to the limited vocabulary, we had to abandon the creation of bigrams and filtering by TF-IDF, which ultimately did not affect the quality of the final modeling, since we did not set the task of exhaustive semantic analysis; identification of topics based on single words it turned out to be sufficient to select all the issues of the newspaper that have information relevant to our research tasks. The Python module Gensim, which is one of the most popular NLP tool packages in the world of modern data science, was chosen as the main library for implementing the program code[5].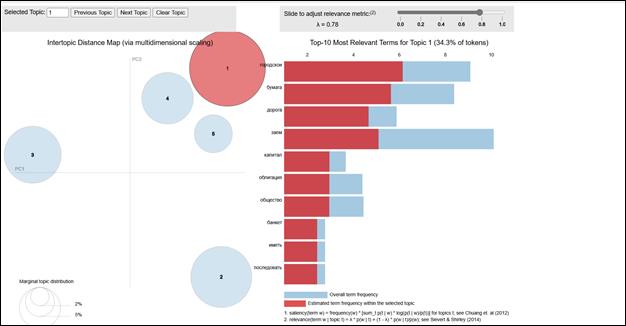 Figure 3. Visualization of the LDA model created for the 3rd page of Issue No. 13521 of the Stock Exchange Gazette dated April 29, 1913. Within the framework of thematic modeling, the expert himself must determine the name for the topic in such a way that it reflects the semantics of individual words forming the topic. For example, according to Figure 8, we can unequivocally state that the words from topic No. 1 clearly gravitate to the topic of urban loans, as indicated by words such as "urban", "loan", "bond", "capital". The architecture of existing LDA models allows you to quickly analyze the content of selected topics based on keyword search, taking into account their "weight". As an algorithm for searching for newspaper issues containing the information we need, we decided to use a search for words forming topics with a threshold value of word weights > 0.01. As semantic units marking the presence of stock information in the simulated document, we used the words listed in Table 1. A list of Fuzzy-match patterns and their corresponding word forms [6]. 2411 LDA models were created for the entire selected collection of texts of the "Stock Market Statements". Of these, our search algorithm identified 457 in the group "containing stock information". Of course, to a large extent, these include the pages with the column of the stock chronicler. As a definite proof of the applicability of LDA models in such source-related problems, we note that the analysis of a random sample of 100 numbers of the "Stock Sheets" showed that not a single column of the chronicler was missed by the search algorithm – each of them was placed in a summary table. As an illustration, we will present a small sample from the fields of the final table, including only those pages and numbers in which it was possible to find stock information outside the column of the stock chronicler. There are 29 such models in total. Table 2 shows examples of sets of topics defined by the model. Table 3 contains a brief description of the materials found on the pages listed in Table 2. In the appendix we have placed photos of the pages presented in both tables. Table 2. Examples of topics and keywords of LDA models for sampling numbers from the collection of "Stock Market Statements" for 1913. | | Topic 1 | Topic 2 | Topic 3 | | Stock exchange statements. 1913, No. 13521 (April 29 (May 12))3.
| '0.021*"place" + 0.012*"factory" + 0.012*"exit" + 0.009*"hour" + 0.009*"station" + 0.009*"octobrist" + 0.009*"academician" + 0.009*"meeting" + 0.009*"again" + 0.009*"water"' |
'0.023*"warehouse" + 0.021*"action" + 0.016*"enterprise" + 0.012*"company" + 0.012*"steamship" + 0.012*"partnership" + 0.012*"transport" + 0.012*"fear" + 0.012*"iron" + 0.007*"balance"' | '0.015*"city" + 0.013*"paper" + 0.012*"loan" + 0.011*"road" + 0.007*"capital" + 0.007*"bond" + 0.007*"company" + 0.007*"share" + 0.006*"special" + 0.006*"have"' | | Stock exchange statements. 1913, No. 13529 (May 3 (16)) 2.
| Russian russian' 0.020*"action" + 0.014*"loan" + 0.011*"worker" + 0.009*"may" + 0.007*"Russian" + 0.007*"bank" + 0.007*"Russian" + 0.007*"market" + 0.007*"enterprise" + 0.007*"new"' | '0.015*"island" + 0.013*"hungarian" + 0.008*"new" + 0.008*"representative" + 0.008*"district" + 0.006*"action" + 0.006*"may" + 0.006*"arrest" + 0.006*"question" + 0.005*"request"' | '0.010*"time" + 0.007*"may" + 0.007*"Lensky" + 0.007*"partnership" + 0.007*"worker" + 0.007*"contract" + 0.007*"power" + 0.006*"last" + 0.006*"sign" + 0.006*"accept"' | | Stock exchange statements. 1913, No. 13543 (May 11 (24)) 1.
| '0.027*"cop" + 0.019*"opera" + 0.019*"summer" + 0.010*"world" + 0.010*"new" + 0.010*"trade" + 0.010*"Nikolaevsky" + 0.010*"bandstand" + 0.010*"piece" + 0.010*"debuts"' | '0.022*"year" + 0.017*"contribution" + 0.017*"question" + 0.017*"increment" + 0.012*"minister" + 0.012*"project" + 0.012*"paper" + 0.012*"government" + 0.012*"cooperate" + 0.012*"reply"' | '0.022*"theater" + 0.015*"box office" + 0.015*"Nevsky" + 0.015*"May" + 0.015*"input" + 0.015*"garden" + 0.013*"prospect" + 0.008*"issue" + 0.008*"day" + 0.008*"address"' | | Stock exchange statements. 1913, No. 13553 (May 17 (30)) 1.
| '0.011*"day" + 0.011*"new" + 0.011*"friend" + 0.011*"special" + 0.011*"performance" + 0.011*"release" + 0.011*"theater" + 0.011*"Slavic" + 0.011*"entrance" + 0.011*"Serbian"' | '0.026*"promotion" + 0.016*"cathedral" + 0.014*"hour" + 0.010*"day" + 0.010*"new" + 0.010*"city" + 0.008*"imperial + 0.008*"august" + 0.008*"local" + 0.008*"face"' | '0.024*"cop" + 0.019*"today" + 0.016*"May" + 0.013*"action" + 0.013*"magician" + 0.013*"Nevsky" + 0.013*"prospect" + 0.013*"theater" + 0.013*"start" + 0.013*"garden"' | | Stock exchange statements. 1913, No. 13565 (May 25 (June 7)) 7.
| '0.014*"personal" + 0.014*"soap" + 0.014*"therefore" + 0.008*"have" + 0.008*"murder" + 0.008*"time" + 0.008*"crime" + 0.008*"money" + 0.007*"station" + 0.007*"good"' | '0.013*"year" + 0.012*"share" + 0.012*"part" + 0.009*"have" + 0.009*"meeting" + 0.009*"general" + 0.009*"shareholder" + 0.009*"warehouse" + 0.009*"hour" + 0.009*"board"' | '0.023*"book" + 0.016*"cow" + 0.012*"terrain" + 0.012*"have" + 0.012*"sale" + 0.012*"right" + 0.008*"forest" + 0.008*"nevsky" + 0.008*"be able" + 0.008*"assign"' | | Stock exchange statements. 1913, No. 13587 (June 8 (21)) 2.
| '0.020*"pirate" + 0.014*"loan" + 0.012*"share" + 0.010*"road" + 0.010*"boat" + 0.008*"oil" + 0.008*"treasury" + 0.008*"iron" + 0.006*"syndicate" + 0.006*"especially"' | '0.011*"committee" + 0.011*"week" + 0.011*"cop" + 0.006*"have" + 0.006*"pain" + 0.006*"accept" + 0.006*"meeting" + 0.006*"money" + 0.006*"bow" + 0.006*"allow"' | '0.013*"trade" + 0.011*"ministry" + 0.011*"capital" + 0.007*"enterprise" + 0.007*"industry" + 0.007*"government" + 0.004*"country" + 0.001*"pirate" + 0.001*"joint stock" + 0.001*"politics"' | | Stock exchange statements. 1913, No. 13597 (June 14 (27)) 2.
| '0.016*"president" + 0.013*"attend" 0.011*"june" + 0.011*"clergy" + 0.011*"law" + 0.008*"consent" + 0.008*"request" + 0.008*"peace" + 0.008*"choice" + 0.006*"case"' | Russian russian 0.022*"share" + 0.016*"Russian" + 0.013*"enterprise" + 0.013*"management board" + 0.013*"bank" + 0.010*"company" + 0.010*"dividend" + 0.010*"report" + 0.010*"head" + 0.010*"Russian"') | '0.018*"deputy" + 0.014*"road" + 0.007*"june" + 0.007*"creditor" + 0.007*"painting" + 0.006*"case" + 0.006*"accept" + 0.006*"also" + 0.006*"member" + 0.006*"yesterday"') | | Stock exchange statements. 1913, No. 13621 (June 28 (July 11)) 3.
| '0.010*"bailiff" + 0.009*"case" + 0.009*"moscow" + 0.008*"help" + 0.007*"acid" + 0.006*"falsification" 0.006*"percent" + 0.006*"salicylic" + 0.005*"plate" + 0.005*"official"' | '0.016*"action" + 0.011*"ruble" + 0.007*"day" + 0.007*"case" + 0.007*"official" + 0.007*"artels" + 0.005*"bailiff" + 0.005*"turn out" + 0.005*"assistant" + 0.005*"service"' | '0.012*"June" + 0.008*"year" + 0.008*"public" + 0.005*"city" + 0.005*"law" + 0.005*"issue" + 0.005*"pass" + 0.005*"management" + 0.005*"life" + 0.005*"publish"' | | Stock exchange statements. 1913, No. 13696 (12 (25) Aug.) 1.
| ('0.012*"shareholder" + 0.012*"day" + 0.012*"room" + 0.012*"action" + 0.012*"crisis" + 0.012*"class" + 0.007*"mixing" + 0.007*"third" + 0.007*"issue" + 0.007*"genuine"') | 0.009*"diplomatic" 0.008*"august" + 0.008*"theater" + 0.008*"business" + 0.008*"great" + 0.008*"July" + 0.008*"have" + 0.008*"negotiations" + 0.008*"question" + 0.008*"close"') |
'0.002*"diplomatic"+ 0.002*"negotiations" + 0.002*"close" + 0.002*"question" + 0.002*"ambassador" + 0.002*"union" + 0.002*"circle" + 0.002*"great" + 0.002*"Balkan" + 0.002*"garden"' | Table 3. The contents of the selected examples with an index to Appendix 2 (corresponding scans of the pages of the "Exchange Statements"). | Stock exchange statements. 1913, No. 13521 (29 Apr. (May 12)). Page 3 Appendix 2.1 | The column "Can the city do without a loan from banks" in the section "State Duma". On the page we find a detailed report of the vowel of the St. Petersburg City Duma on the issue of organizing another loan to cover municipal expenses of St. Petersburg. The author expresses doubt about the need for a new issue and believes that the sale of securities available on the balance sheet of the City Duma will be able to meet the financial needs of the capital. The report is accompanied by detailed statistical calculations with reference to the "report of the St. Petersburg City Public Administration for 1911". | | Stock exchange statements. 1913, No. 13529 (May 3 (16)). Page 2 Appendix 2.2 | The column "Exposing Kerensky", dedicated to the justification of the Lena workers' strike. In the text, members of the board of the Lena partnership (as well as unnamed shareholders) are accused of using administrative ties to conceal the difficult working conditions of workers. | | Stock exchange statements. 1913, No. 13543 (May 11 (24)). 1 page Appendix 2.3 | The "Budget debate" column in the "State Duma" section. The main theses of A.I. Shingarev's speech on the slowness of railway construction are given. This is followed by an assessment of the recent words of Finance Minister V.N. Kokovtsov about the current state of the stock market, which has remained at its levels in the context of a general drop in prices on world markets. | | Stock exchange statements. 1913, No. 13553 (May 17 (30)). 1 page Appendix 2.4 | Announcement of the Board of the Volga Joint-Stock Company of Oil and Chemical Plants "Salolin" on the opening of a subscription to additional issue shares with the conditions of participation. | | Stock exchange statements. 1913, No. 13565 (May 25 (June 7)). Page 7 Appendix 2.5 | Announcement of the Management Board of the St. Petersburg Commodity Warehouses Joint Stock Company on holding an extraordinary general meeting of shareholders with the agenda of the event. | | Stock exchange statements. 1913, No. 13587 (June 8 (21)). Page 2 Appendix 2.6 |
The column "Konovalov's speech" in the section "State Duma". A.I. Konovalov raised the problem of imperfection of the joint-stock legislation. The deputy spoke about the duration of the procedure for the resolution of joint-stock companies and spoke out against the restrictions imposed on the resolution of joint-stock companies for Poles and Jews. | | Stock exchange statements. 1913, No. 13597 (June 14 (27)). Page 2 Appendix 2.7 | Appeal to the bondholders of the Sestroretsk Railway by the chairman of the bankruptcy management, the legal adviser of the Ministry of Finance, K.K. Dynovsky: a message about the liquidation of the current enterprise and the organization of the sale of the road to another company that is ready to undertake obligations for the reorganization of the road. The report of the representative of the group of creditors of the road, L.L. Balinsky, is given that coupons have not been paid by the road since the end of 1906. | | Stock exchange statements. 1913, No. 13621 (June 28 (July 11)). Page 3 Appendix 2.8 | The "Lucky Girl" column. A story about how a certain woman found a bundle of shares in a store that the banker Borisov had lost. This banker was in the house of pre-trial detention on suspicion of embezzlement of these shares. The editorial board expresses suspicion, since the shares "lost" in June were suddenly found in the store in September. | | Stock exchange statements. 1913, No. 13696 (12 (25) Aug.) 1 page Appendix 2.9 | Announcement from the board of the joint-stock company "Severny Lombard" on the exchange of temporary certificates for genuine shares. | *** The analysis of materials found using LDA models was included in the main content of our study devoted to the study of behavioral practices related to the analysis of securities profitability. Thus, an approach was implemented in which the substantive research tasks were solved by traditional historical methods, involving a detailed study of the source text and embedding a separate document into a single system with other available material – archival sources and writings of exchange practitioners [7]. At this stage, we can confirm that within the framework of our research, the use of thematic modeling turned out to be a productive solution for optimizing the process of searching for historical documents in a voluminous collection of digitized historical materials. At the same time, it should be emphasized that in our work thematic modeling was used exclusively as an applied tool to accelerate the search and initial assessment of the information potential of a collection of documents through the analysis of selected topics. Our experience has shown that, at least for "Stock Market Statements", thematic modeling using LDA from the Gensim library does not allow us to draw conclusions from the position of the methodology of content analysis used by us, which involves working with the internal content of the source at the level of analytical practices. The data of our models are too fragmentary, they can only be used for the primary assessment of the topics of the information contained in the source. Of course, we must take into account the possibility of further complication of models through the use of additive regularization [8] and the improvement of OCR recognition towards splitting the page into documents for each separate column, which can significantly increase the ability of the model to capture deeper semantics of newspaper text. Summing up, we would like to note the applied importance of continuing research on the practical applicability of thematic modeling in solving problems of source studies. For interested readers, we leave a link to access the program code and a set of source data proposed by the author [9]. Appendix 1: Dictionary of Definitions
Thematic modeling is a technology of statistical analysis of texts for automatic identification of topics in large collections of documents. The thematic model determines which topics each document belongs to, and what words describe each topic. This does not require manual markup of texts, the model is trained without a teacher. This process can be compared to clustering, but thematic clustering is "soft" and allows the document to belong to several clusters-topics. Thematic modeling does not pretend to understand the meaning of the text, but it is able to answer the questions "what is this text about" or "what common themes do these texts have" [10]. Using thematic modeling, it is important to distinguish between topics and, in fact, topics. Topics are the result of statistical processing of a collection of documents and consist of words that, depending on the chosen statistical model (LDA, LSA, BertTopic, etc.), were assigned a certain significance, on the basis of which the model assumed that these topics (a cluster of significant words) form the topic of the document at the semantic level. However, it is important to emphasize that the procedure for recognizing that a certain topic really reflects the topic present in the text of the document is purely expert. The researcher determines how semantically relevant the set of topics formed by the model turned out to be to the text collection. TF-IDF (from the English TF — term frequency, IDF — inverse document frequency) is a statistical measure used to assess the importance of a word in the context of a document that is part of a collection of documents or corpus. The weight of a certain word is proportional to the frequency of use of this word in the document and inversely proportional to the frequency of use of the word in all documents of the collection. APPENDIX 2 The pages of the newspaper "Birzhevye Vedomosti" identified by the automated search method for the contents of a set of LDA models  Figure 2. 1. Exchange statements. 1913, No. 13521 (April 29 (May 12)). Third page  Figure 2. 2. Exchange statements. 1913, No. 13529 (May 3 (16)). Second page 
Figure 2. 3. Stock exchange statements. 1913, No. 13543 (May 11 (24)). First page 
Figure 2. 4. Stock exchange statements. 1913, No. 13553 (May 17 (30)). Second page 
Figure 2. 5. Exchange statements. 1913, No. 13565 (May 25 (June 7)). Page seven  Figure 2. 6. Exchange statements. 1913, No. 13587 (June 8 (21)). Second page  Figure 2. 7. Exchange statements. 1913, No. 13597 (June 14 (27)). Second page
Figure 2. 8. Stock exchange statements. 1913, No. 13621 (June 28 (July 11)). Third page 
Figure 2. 9. Stock exchange statements. 1913, No. 13696 (12 (25) Aug.). 1 page
References
1. Retrieved from http://docs.historyrussia.org/ru/nodes/1-glavnaya
2. Tze-I Yang, A.J.Torget, & R.Mihalcea. (2011). Topic modeling in historical newspapers.
3. Marjanen, J., Zosa, E., Hengchen, S., Pivovarova, L., & Tolonen, M. (2020). Topic Modelling Discourse Dynamics in Historical Newspapers. DHN Post-Proceedings.
4. Koentges, Thomas. (2020). Measuring Philosophy in the First Thousand Years of Greek Literature.
5. Egger, Roman. (2020). A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts.
6. Galushko, I.N. (2023). Корректировка результатов OCR-распознавания текста исторического источника с помощью нечетких множеств (на примере газеты начала XX века) [Correction of the historical source OCR-recognition using fuzzy sets (on the example of a newspaper from the beginning of the 20th century)]. Historical computer science, 1, 102-113.
7. The presented article is a part of my master's thesis on the topic: "Behavioral aspects of the analysis of the securities profitability in the stock market of the Russian Empire at the beginning of the 20th century: content analysis of exchange narratives." The issues of Birzhevye Vedomosti found by the LDA-algorithm were considered in this paper in combination with the materials of fund No. 143 of the Central state Moscow archive (Moscow Exchange Committee) and the works of exchange practitioners of the early 20th century. (Vasiliev A.A. Exchange speculation, theory and practice. St. Petersburg, 1912.).
8. Vorontsov, K. V. (2020). Вероятностное тематическое моделирование: теория, модели, алгоритмы и проект BigARTM [Probabilistic topic modeling: theory, models, algorithms and the BigARTM project].
9. GitHub. Retrieved from https://github.com/iodinesky/Topic-modeling-of-historical-newspapers
10. Vorontsov, K. V. (2023). Вероятностное тематическое моделирование: теория регуляризации ARTM и библиотека с открытым кодом BigARTM [Probabilistic topic modeling: ARTM regularization theory and BigARTM open source library].
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The reviewed article is devoted to the analysis of the information potential of the collection of historical sources using thematic modeling. In this case, thematic modeling, suitable for various areas of text analysis, is used as a tool for preliminary assessment of the content of a collection of historical documents for the selection of texts relevant to research requests. The press (the newspaper "Birzhevye Vedomosti" for 1905 and 1913) is used as an array of texts on which the proposed methodology is being tested. Digitized sets of newspapers from the website of the Russian National Library (447 issues) were taken for the study. The author set the task of using thematic modeling to automatically search for those newspaper pages where there is information about the functioning of the securities market. The lemmatization method, well-tested in computational linguistics, was used in the search process. Probabilistic LDA models were used, some of which were automatically selected for further analysis as containing stock information. Further, a meaningful analysis of the selected material was carried out. The relevance of the work is beyond doubt, since the search and selection of information necessary for further research is currently a serious problem, which takes a huge amount of time to solve. Any way to adequately address such issues is a great contribution to research practice. The scientific novelty of the work is also obvious. Thematic modeling is almost not mastered in historical science, only the first experiments of its use appear, and the question of the degree of its usefulness within the framework of the creative laboratory of a professional historian still remains open. The article is not constructed in a completely traditional way, since it is largely experimental in nature. After the problem is posed, a logical section begins almost immediately, dedicated to creating a methodology for using thematic modeling to search for information. Next, the search results are analyzed. It is significant that, on the one hand, the author states the productivity of the created methodology for search optimization, on the other hand, he emphasizes that the obtained models are too fragmentary and they can only be used for the primary assessment of the subject of the source information. The article is supplemented with examples of topics and keywords, fragments of selected texts, a dictionary of definitions and photographs of newspaper pages. It should be noted that this certainly interesting and innovative article is intended for a trained reader familiar with the basics of text analysis. At the same time, the thoughtful style of the article makes it easier to understand the rather complex and not always familiar to the traditional view of the historian of the things in question. The bibliography of the article contains a list sufficient for such studies, although it seems that it would not be superfluous to add works in Russian. The article is actually an invitation to an exchange of views and discussions on the issue under consideration, most likely, it is provided with a good citation due to the relevance of the issues considered. The publication of a study related to machine learning methods is designed for a certain range of readers, which, of course, will be quite wide, since any work related to intelligent data processing is of great interest to the scientific community today. The article is recommended for publication.
Link to this article
You can simply select and copy link from below text field.
|
|





