|
MAIN PAGE
> Back to contents
Litera
Reference:
Zaripova D.A., Lukashevich N.V.
Automatic Generation of Semantically Annotated Collocation Corpus
// Litera.
2023. № 11.
P. 113-125.
DOI: 10.25136/2409-8698.2023.11.44007 EDN: QRBQOI URL: https://en.nbpublish.com/library_read_article.php?id=44007
Automatic Generation of Semantically Annotated Collocation Corpus
Zaripova Diana Aleksandrovna
ORCID: 0000-0003-1121-1420
Postgraduate student, Department of Theoretical and Applied Linguistics, Lomonosov Moscow State University
119991, Russia, Moscow, Leninskie Gory str., 1, building 51

|
diana.ser.sar96@gmail.com
|
|
 |
|
Lukashevich Natal'ya Valentinovna
Professor, Department of Theoretical and Applied Linguistics, Lomonosov Moscow State University
119991, Russia, Moscow, Moscow, Leninskie Gory microdistrict, 1, building 51, room 953
|
|
louk_nat@mail.ru
|
|
|
|
DOI: 10.25136/2409-8698.2023.11.44007
EDN: QRBQOI
Received:
12-09-2023
Published:
26-11-2023
Abstract:
Word Sense Disambiguation (WSD) is a crucial initial step in automatic semantic analysis. It involves selecting the correct sense of an ambiguous word in a given context, which can be challenging even for human annotators. Supervised machine learning models require large datasets with semantic annotation to be effective. However, manual sense labeling can be a costly, labor-intensive, and time-consuming task. Therefore, it is crucial to develop and test automatic and semi-automatic methods of semantic annotation. Information about semantically related words, such as synonyms, hypernyms, hyponyms, and collocations in which the word appears, can be used for these purposes. In this article, we describe our approach to generating a semantically annotated collocation corpus for the Russian language. Our goal was to create a resource that could be used to improve the accuracy of WSD models for Russian. This article outlines the process of generating a semantically annotated collocation corpus for Russian and the principles used to select collocations. To disambiguate words within collocations, semantically related words defined based on RuWordNet are utilized. The same thesaurus is also used as the source of sense inventories. The methods described in the paper yield an F1-score of 80% and help to add approximately 23% of collocations with at least one ambiguous word to the corpus. Automatically generated collocation corpuses with semantic annotation can simplify the preparation of datasets for developing and testing WSD models. These corpuses can also serve as a valuable source of information for knowledge-based WSD models.
Keywords:
Natural Language Processing, Automatic Semantic Analysis, Word Sense Disambiguation, Semantic Annotation, Automatic Corpus Generation, Collocation Corpus, Sense Inventory, Related Words, SyntagNet, Thesaurus
This article is automatically translated.
You can find original text of the article here.
Introduction The task of automatic lexical ambiguity resolution (Word Sense Disambiguation, WSD) plays an important role in automatic Natural Language Processing (NLP). The results of WSD affect the quality of solving such higher-level tasks as machine translation [1], information retrieval [2], tonality analysis [3]. However, for training and testing WSD models, voluminous enclosures with semantic markup are needed, the creation of which is a laborious and time-consuming process. The corpus of phrases marked up by values can greatly simplify the markup. The theoretical basis of this approach is the hypothesis of "one meaning per phrase". In this case, there is no need to decide on the markup of each word separately, you can immediately put tags for the lexemes of the phrase found in the corpus. The most famous example of a marked-up corpus of phrases is SyntagNet [4], consisting of more than 80 thousand phrases and available in five languages. The article describes the process of creating such a corpus, the theoretical foundations, as well as different approaches to semantic markup of phrases. The purpose of the work is to explore the possibilities of automatic markup of a phrase in order to create a marked corpus for the Russian language. Section 1 is devoted to the hypothesis "one meaning per phrase" — the theoretical basis for creating a corpus of marked phrases, section 2 provides examples of existing word combinations, including SyntagNet. Section 3 deals with experiments on marking up the corpus of phrases based on the material of the Russian language, section 5 contains an analysis of errors. The article concludes with brief conclusions and directions for future research. The enclosures marked up using the methods described in the article, as well as files with model errors and the "gold standard" are publicly available on GitHub at: https://github.com/Diana-Zaripova/SemanticallyAnnotatedCollocationCorpus /. 1. The hypothesis "one meaning per phrase" In [5], the hypothesis of "one meaning per phrase" was formulated: as part of a phrase, polysemous words occur in one specific meaning. The authors investigated the distribution of the meanings of polysemous words within the framework of phrases based on the material of several types of phrases. The average percentage of confirmation of the hypothesis of "one value per phrase" was 95%. It is important to note that only polysemous words with a binary model of polysemy were considered, that is, having exactly two different meanings. In the article [6], the authors test the hypothesis on polysemous words with more complex, non-binary, models of polysemicity on the material of two corpora. With such input data, the hypothesis was confirmed only in 70% of cases. Separately, the authors note that it is necessary to take into account genres and types of texts when conducting research on ambiguity on the material of more than one corpus. Nevertheless, the results obtained suggest that in a significant proportion of phrases, words appear in the same meanings, which makes it possible to create a corpus of phrases marked by values. 2. Buildings with semantic markup 2.1. SyntagNet SyntagNet (http://syntagnet.org /) is a large-volume (more than 80 thousand phrases) resource containing manually marked up phrases by lexical meanings. The process of creating the corpus, as well as the ideas behind it, are described in detail in the article [4]. The main purpose of creating such lexico-semantic resources is to simplify and accelerate the markup of training and test data collections for training, testing and evaluating the quality of Machine Learning (ML)—based models, often used in the task of automatic resolution of ambiguity. In addition, knowledge about the meaning of a polysemous word within a known phrase can be used when solving a problem using Knowledge-based methods. At the moment, the resource of phrases marked by meanings is available for five languages: English, French, Italian, German and Spanish. The phrases for the SyntagNet corpus (the authors call them lexical combinations) were extracted from the English Wikipedia (https://en.wikipedia.org/wiki/Main_Page ) and the British National Corpus (BNC; [7]), and then marked up manually using the WordNet inventory of values version 3.0. The degree of consistency between annotators, measured on a sample of 500 The number of word combinations was 0.71, most of the discrepancies in the markup were associated with complex cases where there is a variability of tags, a consequence of the high degree of detail of the values in WordNet.
To determine the relevant combinations of words, the authors of the resource performed two procedures for extracting phrases. Firstly, the words w 1, w 2 were extracted from the corpus, which met within a sliding window of three words. The extracted pairs were ordered using the Dice coefficient (Dice's coefficient) multiplied by the logarithm of the frequency of co-occurrence of words: score(w1, w2) = log2(1 + 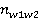 ) )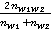 , , where nw1 (i ? {1, 2}) is the frequency of the word w1, and nw1w2 is the frequency of the joint occurrence of two words w1 and w2 within the window. Some filters were applied to the list, in particular, pairs related to each other by one of the five main syntactic relations were selected [4]. Secondly, pairs of words of the following type were extracted: 1) the width of the window is six words; 2) there is no restriction on the type of relationship; 3) pairs already included in the first list are not taken into account and 4) only units found in several dictionaries of the English language and/or dictionaries of phrases were selected. Then eight annotators manually marked up 20,000 first phrases from the first list and 58,000 pairs from the second list using WordNet synsets. The annotators skipped pairs with errors caused by automatic parsing, and pairs in which it is impossible to pick up any of the WordNet synsets for at least one word, as well as idiomatic phrases and verbose named entities. In total, the markup process took 9 months, resulting in 78,000 marked lexical combinations (word pairs) and 88,019 semantic combinations, that is, combinations of WordNet synsets. Example of the markup of phrases in the SyntagNet corpus: (1) a. 09827683n 10285313n baby n boy n b. Synset ID for the first word Synset ID for the second word the first word is part of the speech of the first word the second word is part of the speech of the second word. The authors conducted experiments to evaluate the quality of the WSD model based on knowledge enriched with information from SyntagNet, and compare it with the quality of the same model, but supplemented with information from other lexical knowledge bases, as well as the quality of machine learning models with a teacher. For the experiments, a model based on the personalized PageRank algorithm [8] was chosen, described in detail in the article [9], which was applied to various lexical knowledge bases, including SyntagNet. The average value of the F-1 measure on five English-language datasets was 71.5%; for comparison, the model from [10] based on recurrent neural networks LSTM also demonstrated an F1 measure equal to 71.5% on average on the same five data sets. Based on data collections in different languages (Italian, Spanish, German, French), the average value of the F-1 measure of the model with information from SyntagNet turned out to be the highest among the measured (69.3) and surpassed the results of models based on neural networks. Thus, it seems that the marked-up corpus of phrases is a useful resource, but the markup of the corpus by values is quite time-consuming, which raises the question of automating the markup. 2.2. Marked up data for the Russian language For the Russian language at the moment there are not enough semantically annotated corpora, in principle, we do not know about the existence of word combination corpora at all. However, it is worth mentioning the recent work [11] on the automatic creation of cases with semantic markup based on unambiguous related words. The enclosures obtained during the experiments, as well as the source code, are available at the link: https://github.com/loenmac/russian_wsd_data/tree/master/data . Also in the study [12], the authors manually annotated medium-length texts from the OpenCorpora collection (http://opencorpora.org /). 3. Data and experiments 3.1. Goals, data and preprocessing The authors of the article conducted a number of experiments on the automatic generation of a semantically marked corpus of phrases in the SyntagNet format, but for the Russian language. The purpose of creating the corpus is to simplify the process of data markup for testing and training WSD models based on machine learning, as well as for use in models of automatic resolution of lexical ambiguity based on knowledge and rules. The resolution of ambiguity occurred with the help of semantically close words found within the groupings of phrases by the first and second word. The main idea of the method is to assume that words that occur with the same word in the same position have some semantic affinity that will automatically resolve ambiguity. Examples of such groupings are given below. (2) Example of grouping phrases by the first word: subscriber terminal
subscription book subscriber number subscriber base subscription service subscriber device (3) Example of grouping phrases by the second word: dried apricot apricot harvest apricot stone preparation of apricot. The source of the phrases was the corpus of texts of Russian-language news for 2017 with a volume of 8 GB. At the first stage, all phrases from the corpus were extracted, in which both words refer either to nouns or adjectives, for example: (4) a. local: adjective + noun b. Confederation Cup: noun + noun The phrases were ordered according to the mutual information of MI3: MI3(w1, w2) = 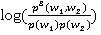 . . Next , the RuWordNet thesaurus was used (https://ruwordnet.ru/ru ), a lexical and semantic resource of the WordNet type for the Russian language [13], for distributing first 100,000 and then 200,000 pairs of words into four categories: a) at least one word is not in RuWordNet; b) the phrase as a separate unit is present in RuWordNet; c) both words are unambiguous and d) at least one word is polysemous. Examples of pairs from each category are given below: (5) a. At least one word is missing in the thesaurus: nonimmigrant visa, walking accessibility, vote of no confidence, phase autofocus; b. The phrase is in the thesaurus as a separate unit: heating season, metering device, chicken egg; c. Both words are unambiguous: local history museum, dean faculty, five-star hotel; d. At least one word has many meanings: wet snow, citizen reception, traffic light signal. The distribution of the first 100,000 and 200,000 pairs in these groups is shown in Table 1: Table 1 | |
The whole phrase is in RuWordNet | At least one word is missing in RuWordNet | Both words are unambiguous | At least one word with multiple meanings | | 100,000 pairs | 1989 (1.989%) | 18660 (18.66%) | 18950 (18.95%) | 60401 (60.401%) | | 200,000 pairs | 2409 (1.2%) | 33123 (16.56%) | 38352 (19.18%) | 126116 (63.06%) | Phrases from the first category are immediately placed in the corpus in a format similar to SyntagNet: word1 word2 <part of speech for word1> <part of speech for word2>. For example: (6) St. Petersburg metro 2642-A Adj 192-N N. Phrases from category d (at least one word is polysemous, and both words are in RuWordNet) are targeted, that is, they need a polysemicity resolution to be entered into the corpus. 3.2. Using related words to resolve ambiguity In all the following stages, only pairs of words from the fourth category (d) took part. At first they were grouped in two different ways: 1) by the first token and 2) by the second token. Then the groups of phrases for the first and second word were supplemented with those pairs of words that were included in the category of phrases contained in RuWordNet as a separate unit, as well as phrases from RuWordNet, which are also marked by values in the thesaurus itself and the first or second word in which coincide with the word according to which the corresponding group is organized.
For example, for the phrase apricot color, in which each word is individually correlated with three RuWordNet synsets, the thesaurus already has markup by values: (7) Apricot blossom 109498-A 106944-N. At the next stage, in order to resolve the ambiguity of words within the word combinations, a search was carried out for close and distant semantically related words within the framework of previously carried out groupings according to the RuWordNet thesaurus: synonyms, hyperonyms, hyponyms, so-called "distant relatives" (described in more detail below). For each word of each pair of words within the group, a list of synonyms, hyponyms and hyperonyms was saved, as well as an array of values — RuWordNet synsets, for which these relatives "vote", i.e. they are semantically close. So, for the relation of synonymy, such synsets are recognized as synsets common to synonyms, for hyperonymy and hyponymy — those values that are associated with the corresponding relation with the hyperonym and hyponym, respectively. An approach to solving the problem of automatic generation of corpora with semantic markup based on words with related meanings is described in the article [11]: the authors use unambiguous related words to automatically resolve ambiguity in the process of automatic markup by values. For example, in the group of phrases for the first word abstract there is a pair (abstract, painting), and in this group for the second word — painting — the following synonyms were found: canvas and painting, and both synonyms vote for one specific value of the target lexeme — 6001-N (‘work of painting’), namely this synset it is included in the intersection of sets of synsets for all three tokens. In another group of phrases formed already around the second word, the hyperonym place was found for the first lexeme of the district in the pair (district, accident), voting for the value 106611-N (‘place, locality'). Synsets separated from the target word by two relations in the thesaurus hierarchy were extracted as "distant relatives", the following types of such chains of relations were considered: 1) s1 ?hyperonym s2 ?hyperonym s3; 2) s1 ?hyponym s2 ?hyponym s3; 3) s1 ?hyperonym s2 ?hyponym s3; 4) s1 ?hyponym s2 ?hyperonym s3. 3.3. Weighing methods After information was collected in each group for all pairs about the kinship relationships of the polysemous words that make up them, as well as what values they vote for, the task arose to resolve the polysemicity of words, namely, to choose only one value and, accordingly, the RuWordNet synset. The authors tested different approaches to choosing the value. The easiest way is to select those pairs that have one value left for each word in the end. This happens when all related words vote for a single word meaning, or when the word was originally unambiguous. However, the number of such pairs turned out to be small: for a sample of 200,000 pairs, there were only 22,073. Therefore, different algorithms for weighing values based on semantically similar words were used. 3.3.1. Simple weighing algorithm A simple weighting algorithm consisted in choosing the value that received the maximum number of votes from the relative values. For those polysemous words where there is only one such value, the algorithm returns this value, otherwise it returns None. 3.3.2. Weighting based on Shortest is-a-Path Also, during the experiments, a weighing algorithm was used based on the distances between synsets according to the RuWordNet thesaurus, namely, the path from the target value to the value of the relative voting for this value [14]. For each value-relative pair, the path was calculated using the following formula: path(a, b) = 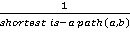 . . Further, the values of the counters for each value are weighted using the obtained values of the thesaurus paths to the relative. 3.3.3. Weighting based on pre-trained Word2Vec vectors
For this method of weighing, vectors of reduced dimension Word2Vec [15] for the Russian language from the Rusvect?r?s resource were used (https://rusvectores.org/ru Russian Russian/) [16], trained on the material of the National Corpus of the Russian Language (NCRR) and the Russian segment of Wikipedia for November 2021 (the corpus size is 1.2 billion words). The dimension of the vectors was 300, the Continuous Bag-of-Words (CBOW) algorithm was used to obtain the vectors. Based on this model, for each pair, the value of a multi—valued word - the related value voting for it, the cosine similarity measure of their Word2Vec vectors was calculated, if any, in the model according to the formula: cosine similarity = 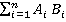 / / 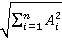 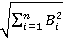 . . The vote counters for a particular value were weighted using the cosine measure of proximity for the value and the relative voting for it. 3.3.4 Weighting based on pre-trained FastText vectors The weighting algorithm based on the cosine measure of proximity of pre-trained vectors of reduced dimension FastText was also tested (https://github.com/facebookresearch/fastText ) [17]. The calculation used the same formula as in subparagraph 3.3.3. 3.3.5. Weighting based on BERT vectors In addition, BERT vectors [18] were used in the experiments: context-free from DeepPavlov through the transformers library for Python and vectors for the target multivalued word in the context of a phrase. Further, the cosine measure of two vectors is also calculated: for a polysemous word in the context of a phrase and for a word with a related meaning also in the context of its phrase. 3.4. Preparation of a test sample and evaluation of the quality of different methods To compare different weighing methods, a manual marking of a sample of 1,735 pairs was performed, which was taken as the "gold standard" for comparison with the result of the work of the weighing algorithms described above and the extraction of phrases for the corpus. At the same time, for all models, at the first step of the work, those pairs were selected in which the ambiguity was completely removed from both words, that is, as a result of counting and weighing votes for all the meanings of the word, in the end, one with the highest weight can be selected, and it goes into the result of the algorithm. To assess the quality of the models, standard metrics were calculated: completeness, accuracy and F1-measure. The results are shown in Table 2 (the number of pairs with completely removed ambiguity and F1-measure): Table 2 | | The number of pairs with completely removed ambiguity | F1-measure | | Before weighing | 3 287 | 0.19 | | Simple weighing algorithm | 23 679 | 0.75 |
| Before weighing + simple algorithm | 26 966 | 0.81 | | Weighting based on is-a Path | 30 997 | 0.81 | | Weighting based on cosine proximity of Word2Vec vectors | 32 117 | 0.79 | | Weighting based on cosine proximity of FastText vectors | 32 780 | 0.81 | | is-aPath + Word2Vec | 33 114 | 0.79 | | is-a Path + FastText | 33 803 |
0.81 | | Weighting based on cosine proximity of BERT context vectors | 32 808 | 0.81 | As you can see from the table, many weighing methods managed to achieve F1-measures of 80% — based on BERT contextual vectors, FastText vectors of reduced dimension, and the shortest path through the thesaurus tree. The same methods allow you to add about 30,000 new marked pairs to the case. 4. Error analysis To analyze the errors, the phrases in which all the models were mistaken were highlighted. There were 257 such phrases. Here is an analysis of these phrases. The category of pairs whose markup was mistaken by all the methods studied includes, among others, those for lexemes in which there were no suitable relative words within the groupings that would help in removing ambiguity. For example, when marking up a phrase ('festive', 'concert'), all seven methods made a mistake in determining the meaning of the second word, defining it as ‘scandal, quarrel’ instead of the correct ‘concert, concert program’, and 80 pairs entered the grouping according to the first word festive. Another example: all models attributed an incorrect value tag to the second lexeme in the phrase ('soldier', 'porridge') — ‘mash (semi-liquid mixture)’, because within the grouping of phrases, semantically different lexemes were selected for the first word: bowler hat, glory, form, letter, halt, overcoat, barracks, grave, widow, order. Within the framework of the phrase ('All-Russian', 'Olympiad'), all models marked the second lexeme as ‘Olympic Games’, however, in the news texts from which the corpus-the source of the phrases was compiled, this phrase is more often used in the context of school Olympiads. In the group of pairs of words for the first word All-Russian, there were several pairs of words denoting sports events of the All-Russian level: training, marathon, rally, competition, regatta, championship, race, tournament. The group also included pairs with second words thematically related to the school subject area — school and lesson, but there were only two of them and they are not related to the desired lexeme. Some errors in the markup were caused by errors at the lemmatization stage, for example, in the phrase ('due', 'image'), the first lexeme was defined as a noun due, formed with the help of adjective conversion, but in fact, in this pair, the first lexeme should be due (adjective). Nevertheless, despite the erroneous marking of some phrases, at least 80% of the phrases were marked correctly by different methods, which allows you to automate the process of marking phrases by values. 5. Conclusion The article considered an approach to the automatic generation of a corpus of phrases in SyntagNet format with semantic annotation. Such cases can greatly facilitate the process of preparing training and test collections for machine learning models, as well as be used as a source of knowledge in rule-based and knowledge-based models. The creation of marked-up word combinations implies the acceptance of the hypothesis "one meaning per phrase". For automatic resolution of lexical ambiguity within phrases, groupings were made by the first and second lexeme and the search for related words within these groupings — synonyms, hyperonyms, hyponyms, more distant relatives, separated from the target lexeme by two steps along the thesaurus tree. The meanings of related words vote for one or another synset of a polysemous word within a phrase. Those pairs that had one synset left for both words after selecting related meanings were added to the corpus. Various methods of weighing the votes received from relatives were applied to the rest of the phrases: a cosine measure of the proximity of the vectors Word2Vec, FastText, contextual vectors BERT, the shortest path along the thesaurus. Most methods achieve an F1 measure of 80% and allow you to expand the corpus of phrases by 30,000 pairs.
As a result of the error analysis, the following pattern was revealed: 68.2% of phrases in which at least one method made a mistake turned out to be a problem for all models. Among the reasons for inaccuracies in semantic markup are errors made at the lemmatization stage, the composition of groupings by the first or second word — words from different subject areas, the predominance of a certain area. As directions for future research, it is possible to study the dependence of the markup quality on the volume of the group, to evaluate the contribution of different semantic relations, and also to evaluate the quality of the methods on a larger collection with manual markup.
References
1. Pu, X., Pappas, N., Henderson, J., & Popescu-Belis, A. (2018). Integrating Weakly Supervised Word Sense Disambiguation into Neural Machine Translation. Transactions of the Association for Computational Linguistics, 6, 635-649. doi:10.1162/tacl_a_00242
2. Blloshmi, R., Pasini, T., Campolungo, N., Banerjee, S., Navigli, R., & Pasi, G. (2021). IR like a SIR: Sense-enhanced Information Retrieval for Multiple Languages. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 1030-1041. doi:10.13140/RG.2.2.30354.58567
3. Seifollahi, S., & Shajari, M. (2019). Word Sense Disambiguation Application in Sentiment Analysis of News Headlines: an Applied Approach to FOREX Market Prediction. Journal of Intelligent Information Systems, 52, 57-83. doi:10.1007/s10844-018-0504-9
4. Maru, M., Scozzafava, F., Martelli, F., & Navigli, R. (2019). SyntagNet: Challenging Supervised Word Sense Disambiguation with Lexical-semantic Combinations. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 3532-3538. doi:10.18653/v1/D19-1359
5. Yarowsky, D. (1993). One Sense per Collocation. In Human Language Technology: Proceedings of a Workshop Held at Plainsboro, New Jersey, 266-271. doi:10.3115/1075671.1075731
6. Martinez, D., & Agirre, E. (2000). One Sense per Collocation and Genre/Topic Variations. 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, 207-215. doi:10.3115/1117794.1117820
7. Leech, G. (1992). 100 Million Words of English: the British National Corpus (BNC). Language Research, 28(1), 1-13.
8. Haveliwala, T.H. (2002). Topic-sensitive PageRank. Proceedings of the 11th International Conference on World Wide Web, 517-526. doi:10.1145/511446.511513.
9. Agirre, E., López de Lacalle, O., & Soroa, A. (2014). Random Walks for Knowledge-based Word Sense Disambiguation. Computational Linguistics, 40(1), 57-84. doi:10.1162/COLI_a_00164
10. Yuan, D., Richardson, J., Doherty, R., Evans, C., & Altendorf, E. (2016). Semi-supervised Word Sense Disambiguation with Neural Models. Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, 1374-1385.
11. Bolshina, A., & Loukachevitch, N. (2020). Monosemous Relatives Approach to Automatic Data Labelling for Word Sense Disambiguation in Russian. Linguistic Forum 2020: Language and Artificial Intelligence, 12-13.
12. Kirillovich, A., Loukachevitch, N., Kulaev, M., Bolshina, A., & Ilvovsky, D. (2022). Sense-Annotated Corpus for Russian. Proceedings of the 5th International Conference on Computational Linguistics in Bulgaria (CLIB 2022), 130-136.
13. Loukachevitch, N.V., Lashevich, G., Gerasimova, A.A., Ivanov, V.V., & Dobrov, B.V. (2016). Creating Russian WordNet by Conversion. Computational Linguistics and Intellectual Technologies: papers from the Annual conference “Dialogue”, 405-415.
14. Liu, X.Y., Zhou, Y.M., & Zheng, R.S. (2007). Measuring Semantic Similarity in WordNet. 2007 International Conference on Machine Learning and Cybernetics, 6, 3431-3435. doi:10.1109/ICMLC.2007.4370741
15. Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. Advances in Neural Information Processing Systems, 26, 3111-3119.
16. Kutuzov, A., & Kuzmenko, E. (2017). WebVectors: a Toolkit for Building Web Interfaces for Vector Semantic Models. Analysis of Images, Social Networks and Texts: 5th International Conference, AIST 2016, Revised Selected Papers 5, 155-161. doi:10.1007/978-3-319-52920-2_15
17. Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Llinguistics, 5, 135-146. doi:10.1162/tacl_a_00051.
18. Devlin, J., Chang, M.W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT, vol. 1, 4171-4186. doi:10.18653/v1/N19-1423
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The article "Automated creation of a semantically marked corpus of phrases" submitted for consideration, proposed for publication in the journal "Litera", is undoubtedly relevant, due to the author's appeal to the study of automated processing of the language corpus, which is important nowadays, due to the increasing role of technology in our lives. The article describes the process of creating such a corpus, the theoretical foundations, as well as different approaches to the semantic markup of phrases. The purpose of the work is to explore the possibilities of automatic markup of a phrase in order to create a marked—up corpus for the Russian language. The article is innovative, one of the first in Russian linguistics devoted to the study of such issues. The article presents a research methodology, the choice of which is quite adequate to the goals and objectives of the work. The author refers, among other things, to various methods to confirm the hypothesis put forward, namely the statistical method, the method of generalization, modeling and the method of semantic analysis. The theoretical fabrications are illustrated with language examples, and convincing statistical data obtained during the study are presented. This work was done professionally, in compliance with the basic canons of scientific research. The research was carried out in line with modern scientific approaches, the work consists of an introduction containing the formulation of the problem, the main part, traditionally beginning with a review of theoretical sources and scientific directions, a research and a final one, which presents the conclusions obtained by the author. It should be noted that the conclusion requires strengthening, it does not fully reflect the tasks set by the author and does not contain prospects for further research in line with the stated issues. The practical results of the application of the described technique are publicly available on GitHub at: https://github.com/Diana-Zaripova/SemanticallyAnnotatedCollocationCorpus /. The bibliography of the article contains 17 sources, among which works are presented exclusively in a foreign language. Unfortunately, the article does not contain references to fundamental works of Russian researchers, such as monographs, PhD and doctoral dissertations in Russian. The comments made are not significant and do not detract from the overall positive impression of the reviewed work. In general, it should be noted that the article is written in a simple, understandable language for the reader. The work is innovative, representing the author's vision of solving the issue under consideration and may have a logical continuation in further research. The practical significance of the research lies in the possibility of using its results in the teaching of university courses in lexicology and lexicography, mathematical linguistics, as well as courses in interdisciplinary research on the relationship between language and society. The article will undoubtedly be useful to a wide range of people, philologists, undergraduates and graduate students of specialized universities. The article "Automated creation of a semantically marked corpus of phrases" can be recommended for publication in a scientific journal.
Link to this article
You can simply select and copy link from below text field.
|
|





