|
MAIN PAGE
> Back to contents
Security Issues
Reference:
Strizhkov V.A.
Application of machine learning methods to counter insider threat to information security
// Security Issues.
2023. № 4.
P. 152-165.
DOI: 10.25136/2409-7543.2023.4.68856 EDN: JZMHXQ URL: https://en.nbpublish.com/library_read_article.php?id=68856
Application of machine learning methods to counter insider threat to information security
Strizhkov Vladislav Alexandrovich
Postgraduate student, Information Security Department, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.

|
218668@edu.fa.ru
|
|
 |
|
DOI: 10.25136/2409-7543.2023.4.68856
EDN: JZMHXQ
Received:
31-10-2023
Published:
31-12-2023
Abstract:
The subject of the study is the problem of internal threats to information security in organizations in the face of malicious insiders, as well as negligent employees. The object of the study is machine learning algorithms in terms of their applicability for detecting abnormal behavior of employees. The author delves into the problems of insider threat, and also considers various approaches to detecting malicious user actions, adapting these concepts to the most suitable machine learning algorithms in terms of functionality, implemented further in the framework of the experiment. The emphasis is on the insufficiency of existing generally accepted security measures and policies and the need to improve them through new technological solutions. The main result of the conducted research is an experimental demonstration of how controlled machine learning and data mining can be effectively used to identify internal threats. During the experiment, a realistic set of input data is used, compiled on the basis of real cases of insider activity, which makes it possible to evaluate the operation of machine learning algorithms in conditions close to combat. When comparing the results obtained, the most efficient algorithm is determined, which is preferable for future studies with a larger data set. A special contribution of the author is a fresh look at the understanding of the insider threat and an experimentally substantiated argument in favor of a new approach to countering this threat, combining a complex of diverse measures. Thus, the work involves both mathematical methods on which the logic of machine-learning algorithms is based: classification, regression, adaptive enhancement, etc., and linguistic methods used for preprocessing the input data set, such as stemming, vectorization and tokenization.
Keywords:
insider threat, internal intruder, machine learning, supervised learning algorithms, adaptive boosting, anomalous behavior, classification algorithms, logistic regression, vectorization, information security
This article is automatically translated.
You can find original text of the article here.
1. Introduction In the modern world, insiders can be a serious threat to the organization in which they work, so preventing malicious actions by insiders in the organizational system is an important task for cybersecurity. Organizational security measures are well known to an experienced insider, and he can easily find loopholes, and existing security policies in organizations are focused more on external threats, sometimes ignoring the possibility of internal threats. If the necessary security measures are not implemented in the company, the insider gets space to steal important data without specific obstacles, which causes irreparable damage to the organization, both direct material and indirect image [1]. In this regard, in the current realities, when the perimeter of protection against hacker and other external threats has already been built at a sufficiently high and technological level, it is worthwhile to shift the focus from external threats to internal ones for a while, give importance to this problem and find new solutions. However, difficulties are often associated with the fact that there is little real statistical data on the insider threat and the corresponding damage [2]. The insider threat can be roughly divided into three main categories that companies regularly have to deal with: a malicious insider, a "careless" insider and a compromised insider. A malicious insider is a type of insider who intentionally wants to steal protected data, disclose information, or use any other means to harm an organization. An insider threat "due to negligence" or an unintended insider occurs when employees do not know security rules or do not follow security procedures, exposing the company to the risk of infection with malicious software and data disclosure, thus becoming unintentional internal violators. Finally, a compromised insider threat is a malicious insider whose credentials have been compromised by a hacker through social engineering, credential collection, phishing email messages, or methods that exploit the vulnerability to steal data or through illegal financial transactions. Along with the cybernetic and technical scenario, one of the most important tasks is the identification and implementation of behavioral (sociotechnical) indicators of insider threat risk. When we look at the data available to verify the behavior of an insider threat, we often ignore the human side of the issue [3]. This problem has been investigated by experts for many years, and there are already noticeable successes in the process of finding a solution. One of them is text analysis using machine learning algorithms. In addition, there is evidence that learning algorithms with a teacher provide better memorization compared to semi-supervised and unsupervised methods when they get more details [4]. In this article, special attention is paid to the categorization of e–mail from a special dataset (hereinafter referred to as ND), which contains realistic examples of insider threats based on gamified competition obtained using various machine learning technologies. First, preprocessing techniques such as stemming, stopword removal, and tokenization are used to clean up the data. After that, Adaboost learning algorithms, as well as Bayes algorithm, logistic and linear regression, and the support vector machine method are applied to the dataset to obtain information. The results obtained using these algorithms are compared and analyzed. The study is divided into several sections. The existing approaches related to this study are presented in section 2. Information about the dataset and methodology is discussed in section 3. The results of the study are presented in section 4. Upcoming work and concluding observations are discussed in the fifth section. 2. Existing approaches The scientific community is faced with the fundamental problem of detecting an insider threat. The public sector and cybersecurity services refer to the same problem, calling for effective strategies to be found. The available works of scientists devoted to the issue are presented below. Of course, there are many of them, in this case, those that involve machine learning technologies have been selected, and therefore they deserve special attention, since they can be further used to contrast the results of the current study. Diop Abdoulaye et al. [5] proposed a model for detecting behavior anomalies, which is a step towards building a custom behavior verification system. This method combines the machine learning classification method and graph-based methods based on linear algebra and parallel computing procedures. The accuracy of their model is 99% on a representative set of access control data. Duke Lee et al. [6] proposed an intelligent user-oriented system based on machine learning. In order to closely monitor the insider, malicious user behavior was tracked using detailed machine learning analysis in real-world conditions. To provide an actual approximation of system performance, a comprehensive analysis of popular internal threat scenarios with multiple performance indicators is provided. The results of the study indicate that an artificial intelligence (AI)-based monitoring and detection system can detect new internal threats based on unmarked data with high accuracy, since it can be trained very effectively. The study says that approximately 85% of such insider threats have been successfully identified with a false positive rate of only 0.78%. Malvika Singh et al. [7] carried out insider threat detection by working on another approach – profiling user behavior to observe and study the sequence of actions of user behavior. The researchers presented a hybrid machine learning model consisting of "ultra-precise neural networks (CNN)" to identify stabilizing outliers in behavioral patterns, achieving detection accuracy of 0.9042 and 0.9047 on training and test data, respectively. Following this, Ju Ming Lu et al. [8] proposed a system based on a deep neural network with long short-term memory (LSTM), called the "Insider Catcher", for learning system file entries that act as a natural structured sequence. To distinguish normal behavior from malicious behavior, their system uses patterns that define user behavior. Experiments and results showed that the proposed method demonstrated better performance than the ubiquitous log-based anomaly detection system. The performance of this system is sufficient for real-time online scenarios. Finally, we can note the approach of Hawai et al. [9], which uses the "Isolation Forest" - an unsupervised learning algorithm to detect anomalies and identify insider threats from logs taken from the network.
3. Research methodology In this section, we will implement some of the methods that have been adapted for data analysis. This includes defining a dataset, methodologies such as machine learning techniques, and detecting abnormal emails. Figure 1 shows a brief description of our system, which consists of four blocks: a block of data collection and preprocessing, a block of data transformation, a block of supervised learning and a block of classification, respectively. Each block is described in detail in the following subsections. 
Fig. 1. Vector representation of text data 3.1. Data set The dataset (ND) was collected based on the actual user interaction with the host machine, which contains both legitimate user data and malicious insider instances (masqueraders and traitors) [10]. The ND contains data obtained from six data sources (keystrokes, mouse, host monitor, network traffic, email, and login), as well as additional results from the psychological personality questionnaire. The ND contains the behavior of 24 users that were collected within 5 days. It contains twelve copies of the masquerade, each lasting 90 minutes, and five potential copies of the traitor, each lasting 120 minutes. Emails have been found to be an important attribute for detecting internal threats. In the order in which users send emails, the activity of all users is contained in a single file. It includes information such as timestamp, header, sender, recipient, functions extracted from the body of the email. 3.2. Machine Learning This method allows you to identify patterns of dangerous behavior of internal violators. The article discusses the following learning algorithms: 1) Supervised learning – can be fruitful when a confirmatory answer is known. All emails from the dataset are classified as "Regular Email" or "Abnormal Email". The tasks of teaching with a teacher are divided into two categories: "Classification" and "Regression". 2) Classification – the results are predicted in a discrete output. The input variables are divided into discrete categories. Classification algorithms: · The K-nearest neighbor algorithm examines the entire dataset for the k number of most homogeneous or adjacent cases that point to the same model as the row with the lost data. The element is discarded by the majority of votes of its neighbors, the element is assigned to the most common class among the nearest neighbors k [11]. · The Bayes algorithm is a simple learning algorithm that uses the Bayes rule simultaneously with the strict assumption that attributes are self–sufficient for a given class. Despite the fact that this presumption of freedom is often abused in everyday life, nevertheless, Bayes still provides accuracy for competitive classification [12, 13]. · The support vector machine is a linear model for classification. The algorithm creates a line or hyperplane that divides the data into classes. [14]. 3) Regression – the results are predicted in a continuous output. Input variables are mapped to a continuous function. Regression algorithms: · Linear regression – consists in finding the most effective straight line across the lines. The line that fits best is called the regression line. The linear regression algorithm studies the linear function f(x,w), which is a mapping of f :?x ? y. It is a linear combination of a fixed set of linear or nonlinear functions of the input variable, denoted as ?i(x) and called basic functions. The form f (x, w) is equal to: where w is a weight vector or matrix w = (w1, ..., w D)T , and ? = ?(1, ... ,D)T .
· Logistic regression is an analytical method similar to linear regression that discovers an equation to predict the outcome for a binary variable Y from one or more response variables, X. Response variables can be categorical or continuous, unlike linear regression, since the model does not require continuous data. To predict group membership and finite type placement, an iterative maximum likelihood method is used instead of the least squares method, using a logarithmic ratio of chances rather than probabilities [15]. 4) Adaboost, known as "Adaptive Enhancement", is a meta-learning algorithm that combines weak classifiers into a unique strong classifier. AdaBoost allows you to classify instances, giving more weight to complex ones and less to those that have already been processed well. AdaBoost is designed to solve classification and regression problems [16]. 3.3. Detection of abnormal emails Insiders can cause huge damage in the current IT environment, and we cannot completely prevent the damage from this. Existing information security tools and systems often need to be improved to mitigate the possible consequences of insider exposure. This is expressed in an appropriate request from specialized specialists in the field of information technology and information security, for whom research on new ways to detect abnormal activity is especially valuable [17, 18]. To determine the compliance limit for information security automation, the human factor should also be studied. For this purpose, e-mail is excellent as a medium for detecting insider threats [19]. Finally, in order to get an idea of the real applicability of the described machine learning methods and algorithms, let's proceed to the experimental part of the study. 4. Experiments and results Implemented a Python system with Tensorflow as a backend. Anaconda IDE was used for development. To evaluate possible abnormal emails, you need to follow five steps. At the first stage, data is collected from the ND repository. The preprocessing steps include detecting missing values, removing stop words, stemming, and tokenization. This is followed by data transformation, in which the text data is converted to a vector form. After preprocessing, machine learning algorithms were applied to classify emails. These steps are described in stages in the following sections, which is done for the convenience of readers and, first of all, researchers in the considered and related scientific fields, in particular, for Data Science specialists and data analysts. The separation allows you to determine the place and role of work in the overall sequence of actions for each of them in accordance with their profile. Attracting the attention of various kinds of specialists to the subject under consideration is especially important, including for reasons of the need for further research. 4.1. Data Cleaning Combining the entire dataset and analyzing it for consistency and any inconsistencies that need to be corrected. In addition, all lines containing null values of the message text are deleted or filled in, as suggested in a certain scheme. 4.2. Pre-processing of data The dataset consists of .csv files that are sent by email from different users. All email files are combined into one file. It has a user ID, email content, tweets, and an email tag in the file. After that, the data set is preprocessed, consisting of the following steps. 1) Removing stop words – that is, words that have no effect in the same sentence. You can easily ignore them without losing the context of the sentence. 2) Stemming is a method of minimizing a word to its base, which is attached to suffixes and prefixes or to the roots of words, known as a lemma, called stemming. Stemming is vital for processing and understanding natural language. 3) Tokenization is a method of dividing text into parts called tokens. Tokens can be individual words, phrases, or even whole sentences. In the tokenization method, you can discard some characters, such as punctuation marks. Tokens are usually used as input data for processes such as vectorization. 4.3. Data Conversion Data conversion is a method of converting data from one format to another. Email data consists of text data that is converted to a vector format, as shown in Figure 2. After converting text data to vector form, TF-IDF vectorization changes the raw directory cluster to a TF-IDF function matrix, as shown in Figure 3. 
Fig. 2. Vector representation of text data 
Fig. 3. Encoding data via TF-IDF 4.4. Machine Learning methods The algorithm for the proposed Python framework with tensor flow in the backend is shown in Table 1. Table 1 The algorithm of supervised learning |
Input data | Training data D = x,y | | Output data | Separation of normal and malicious emails | | Step 1 | Data preprocessing and time reduction | | Step 2 | Formation of the TF-IDF matrix | | Step 3 | Study of AdaBoost classifiers, k nearest neighbor, support vector machine, logistic and linear regression, Bayes algorithm based on a dataset | | Refund | St(x) = h(AdaBoost) | Several separate classifiers were run on the dataset. Namely, AdaBoost, k nearest neighbor, support vector machine, logistic regression, linear regression and Bayes algorithm. Single classifiers give satisfactory performance, with a maximum value of 0.983. The performance of the model was measured using performance indicators such as accuracy (Accuracy) and memorization (Zap). The results obtained using the models are presented in the Table. 2 and in Figure 4. Here, | Exactly | 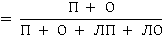
| (3) | | Zap | 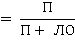
| (4) | where: N = positive (correctly defined normal emails); O = negative (correctly identified malicious emails); LP = false positive (malicious emails mistaken for normal); LO = false negative (normal emails mistaken for malicious). Table 2
The results of single classifiers on the test set | Classifier | Accurate (%) | Zap (%) | The matrix | | Normal | Malicious | | AdaBoost | 98,3 | 98 | 495(P) | 8(LP) | | 9(LO) | 488(O) | | k nearest neighbor | 96 | 97 | 488(P) | 24(LP) | | 16(LO) |
472(O) | | The support vector machine | 95 | 95 | 478(P) | 24(LP) | | 16(LO) | 472(O) | | Logistic regression | 94,8 | 93 | 479(P) | 27(LP) | | 25(LO) | 469(O) | | Linear regression | 93,2 | 91 | 450(P) |
18(LP) | | 52(LO) | 478(O) | | Bayes algorithm | 73,7 | 76 | 374(P) | 166(LP) | | 130(LO) | 336(O) | 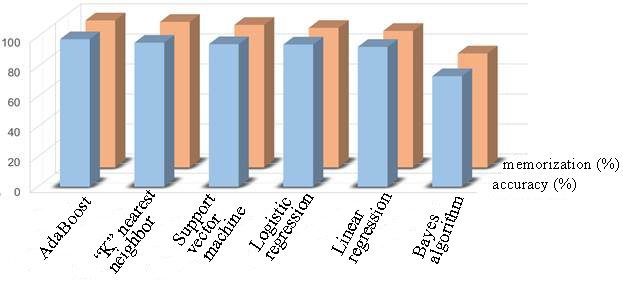
Figure 4. A graph representing the results of learning algorithms with a teacher After studying the results obtained, we come to the conclusion that among the proposed algorithms, the best is the method of "adaptive enhancement" (AdaBoost), since it allows us to obtain the highest value of accuracy and memorization. The first indicator characterizes the possibility of correct identification of both normal and malicious objects from their entire number, demonstrating the real practical applicability of the method within the framework of the task of searching for abnormal behavior in information systems of organizations. The second indicator is a reference to the machine learning capabilities theoretically presented in Section 3.2. Only now it is an empirically obtained assessment of their capabilities, it can also be considered as an indirect characteristic of the depth of learning of the algorithm itself, coupled with its applicability to such a problem statement. Literally, this can be described as the ability to identify objects that do not contain anomalies based on their reproduction from memory from among normal objects. It is also worth mentioning that with the complex use of several algorithms at the same time, the results in the form of accuracy and memorization characteristics do not add up and do not increase, and the resulting efficiency coincides with the results of the method with maximum efficiency among the selected in each case. For example, a complex consisting of the classifiers "support vector machine" and "logistic regression" show an efficiency equal to 95% in both indicators, as well as a single classifier "support vector machine". 5. Conclusion The article examines methods for identifying abnormal employee emails. Based on experiments, it can be concluded that it is possible to achieve better classification accuracy of mail messages using a combination of preprocessing methods such as TF-IDF and the AdaBoost model, which correctly classifies 98.3% of malicious emails. A publicly available dataset based on realistic examples of insider threats was used for experiments using various machine learning technologies, the result of which surpassed existing methods applied to this dataset. The results obtained can be extremely useful to specialists in the field of information technology and information security, in particular, data analysts, Data Science specialists, scientific researchers in the considered and related fields, as well as for technical specialists of law enforcement agencies.
Comparing the obtained values of the accuracy of identifying insider threats with the results of the approaches proposed earlier by foreign researchers, we find that they were surpassed in a number of indicators. For example, the accuracy of anomaly detection obtained in the work of Duke Lee et al. [6], as already indicated earlier in section 2, was approximately 85%, whereas we achieved an accuracy of 98.3%. The machine learning model proposed by Malvika Singh et al. [7] consists of "ultra-precise neural networks", demonstrated an accuracy of about 90%, which was also surpassed with the help of five of the six tested classifiers. Serious opponents in this field can rightfully be considered Diop Abdoulaye et al. [5], who combined machine learning methods and methods based on linear algebra and parallel computing procedures, while achieving accuracy, in some cases reaching 99%. Contrasting the results obtained, it should be noted that our proposed approach allows, using only the methods of controlled machine learning, to obtain indicators that are less than one percent inferior, which varies within the margin of error with a relatively small array of input data used. At the same time, the demonstrated approach is an attractive alternative for the end developer of a software solution, since it allows you to simplify it by limiting yourself to machine learning algorithms and not heaping up the program code with redundant algebraic calculations. A potential direction for future research is the adaptation of this model to specific technical means and solutions that are widely known and widely used as the main components of an information security system. In addition, do not forget that the experiment involves an array limited to a thousand records. This limitation is dictated by the capacities of the equipment used on the test bench. Of great importance are further experiments in the format of the proposed model on a larger set of input data, close to the real volume that circulates in the information systems of organizations, using appropriate hardware and software, the resources of which are sufficient to carry out the necessary calculations and emulations in larger quantities. This will allow you to adjust the percentage of accuracy of anomaly detection by various classifiers, and probably even identify the inexpediency of using some of them. But not only quantitative, but also qualitative improvement of the described methods is appropriate in the further development of the affected issues. So, if we focus on deeper machine learning, then there is a high probability of increasing the effectiveness of the proposed methods without resorting to the help of resource-intensive equipment, this area of research is more the prerogative of Data Science specialists.
References
1. Shugaev, V V.A., & Alekseenko, S.P. (2020). The classification of insider threats information, Bulletin of the Voronezh Institute of the Ministry of Internal Affairs of Russia, 2, 143-153.
2. Nicola d'Ambrosio, Gaetano Perrone, Simon Pietro Romano. (2023). Including insider threats into risk management through Bayesian threat graph. Computers & Security, 133, 1-21. doi.org/10.1016/j.cose.2023.103410
3. Karen Renaud, Merrill Warkentin, Ganna Pogrebna, Karl van der Schyff. (2023). VISTA: An Inclusive Insider Threat Taxonomy, with Mitigation Strategies. Information & Management, 60(8), 1-37. doi.org/10.1016/j.im.2023.103877
4. Omar, S., Ngadi, A., & Jebur, H. H. (2013). Machine learning techniques for anomaly detection: an overview. International Journal of Computer Applications, 79(2), 33-41. doi.org/ 10.5120/13715-1478
5. Diop, A., Emad, N., Winter, T., Hilia, M. (2019). Design of an Ensemble Learning Behavior Anomaly Detection Framework, International Journal of Computer and Information Engineering, 13(10), 551-559. doi.org/10.5281/zenodo.3566299
6. D. C. Le, N. Zincir-Heywood and M. I. Heywood. (2020). Analyzing Data Granularity Levels for Insider Threat Detection Using Machine Learning, IEEE Transactions on Network and Service Management, 17(1), 30-44. doi.org/10.1109/TNSM.2020.2967721
7. M. Singh, B. M. Mehtre & S. Sangeetha. (2019). User Behavior Profiling using Ensemble Approach for Insider Threat Detection, IEEE 5th International Conference on Identity, Security, and Behavior Analysis (pp. 1-8). Hyderabad, India.
8. Jiuming, Lu & Raymond, K. Wong. (2019). Insider Threat Detection with Long Short-Term Memory, Proceedings of the Australasian Computer Science Week Multiconference (pp. 1-10). New York: Association for Computing Machinery.
9. Gavai, G. Sricharan, K. Gunning, D. Hanley, John Singhal, M. Rolleston, Robert. (2015). Supervised and Unsupervised methods to detect Insider Threat from Enterprise Social and Online Activity Data, Journal of Wireless Mobile Networks, Ubiquitous Computing, and Dependable Applications (JoWUA), 6(4), 47-63. doi.org/10.22667/JOWUA.2015.12.31.047
10. Flavio Homoliak, Harill, Athul Toffalini, John Guarnizo, Ivan Castellanos, Juan Mondal, Soumik Ochoa, Mart´ın. (2018). The Wolf of SUTD (TWOS): A dataset of malicious insider threat behavior based on a gamified competition, Journal of Wireless Mobile Networks, 9(1), 54-85. doi.org/10.22667/JOWUA.2018.03.31.054
11. Kenyhercz, Michael W. and Passalacqua, Nicholas V. (2016). Missing data imputation methods and their performance with biodistance analyses, Biological Distance Analysis, 181-194. doi.org/10.1016/B978-0-12-801966-5.00009-3
12. Askari, Armin, Alexandre d’Aspremont, & Laurent El Ghaoui. (2020). Naive feature selection: sparsity in naive bayes, International Conference on Artificial Intelligence and Statistics (pp. 1813-1822). PMLR.
13. Bagaev, I., Kolomenskaya, M., Shatrov, A. (2019). The algorithm of the naive Bayes method in binary classification problems on the example of the santander dataset from the kaggle platform, Artificial intelligence in solving urgent social and economic problems of the XXI century: collection of articles based on the materials of the Fourth All-Russian Scientific and Practical Conference Part I. Perm. state. National. research. university, Perm, 32-36.
14. George A.F., Alan J. Lee. (2012). An overview on theory and algorithm of support vector machines, Journal of University of Electronic Science and Technology of China, 1(40), 2-10. doi.org/10.3969/j.issn.1001-0548.2012.01.001
15. Minjiang Fang, Dinh Tran Ngoc. (2023). Building a cross-border e-commerce talent training platform based on logistic regression model, The Journal of High Technology Management Research, 34(2), 1-12. doi.org/10.1016/j.hitech.2023.100473
16. Sokolov V., Kuzminykh I., Ghita B. (2023). Brainwave-based authentication using features fusion, Computers & Security, 129, 1-12. doi.org/10.1016/j.cose.2023.103198
17. Polyanichko, M. Basic methodology for countering internal threats to information security, Bulletin of Modern Research, 9.3(24), 314-317.
18. Karpunina, K. (2022) Problems of information security security of russian enterprises in a crisis, Economic security of society, the state and the individual: problems and directions of provision: collection of articles based on the materials of the IX scientific and practical conference, under the general ed. Taktarova, S., Sergeeva, A.. Moscow: Publishing House "Pero", 210-213.
19. Arnau Erola, Ioannis Agrafiotis, Michael Goldsmith, Sadie Creese. (2022). Insider-threat detection: Lessons from deploying the CITD tool in three multinational organisations, Journal of Information Security and Applications, 67, 1-22. doi.org/10.1016/j.jisa.2022.103167
First Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The subject of the study. Based on the title, the article should be devoted to the application of machine learning methods to counter the insider threat to information security. The content of the article corresponds to the stated topic. The research methodology is based on the use of data analysis and synthesis methods. It is valuable that the author graphically demonstrates the presented results. The author also claims that "the dataset was collected based on the actual user interaction with the host machine, which contains both legitimate user data and malicious insider instances." This indicates a deep immersion in the content of the issues under consideration, since the author's conclusions should be based on the study of real numerical data. The relevance of the study of issues related to countering the insider threat to information security is beyond doubt, because it meets the national interests of the Russian Federation and makes a positive contribution to ensuring the technological sovereignty of the Russian Federation. There is a scientific novelty in the material submitted for review. In particular, it consists of a graphical representation of the vector representation of text data. It is also recommended to indicate potential users of the obtained research results in the text of the article. Style, structure, content. The style of presentation is predominantly scientific, but some judgments are made in the conversational genre: for example, the author says "We successfully coped with over-fitting in a small data set using simple models." This style is not allowed for a scientific article. The structure of the article, as a whole, is built correctly. The content of the article is made at a high level in terms of the first structural elements, but the final part is done superficially. In particular, the author concludes that "Thus, the proposed AdaBoost method allows to obtain the highest accuracy value." On the basis of which such a conclusion is made? This does not follow logically from the text of the article: it is necessary to link the conclusion with the stated text. Moreover, it is noteworthy that there is no list of identified problems when applying the listed conclusions and options for eliminating them. It would also be interesting to explore the possibility of using the methods in a complex. Perhaps the author has his own methodology based on the use of a set of methods. In the final part of the article, it would also be interesting to identify potential areas for further research. Bibliography. Familiarization with the list of references allows us to conclude that it contains 15 titles. At the same time, attention is drawn to the fact that 14 of the 15 sources are foreign. When finalizing the article, the author is recommended to increase the number of domestic scientific publications used. This will allow us to take into account modern Russian trends in the study of the use of machine learning methods to counter the insider threat to information security. Appeal to opponents. Despite the existence of a generated list of sources, no scientific discussion on the results of the study is presented in the text of the article. At the same time, this would enhance the level of scientific novelty and the depth of immersion in the issues raised. Conclusions, the interest of the readership. Taking into account all of the above, the article requires correction (at least in conclusion), after which the question of the expediency of its publication can be resolved. Potentially, this article will be in high demand from a wide range of readers: teachers, researchers, analysts and representatives of state authorities of the Russian Federation and subjects of the Russian Federation.
Second Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The reviewed work is devoted to ensuring cybersecurity and countering the insider threat to information security using machine learning methods to detect abnormal emails. The research methodology is based on the analysis of data sets containing examples of insider threats received by e-mail, the use of classical machine learning methods, the use of Adaboost (adaptive enhancement) teacher learning algorithms, Bayes, logistic and linear regression, and the support vector machine method. The authors attribute the relevance of the work to the fact that preventing malicious actions by insiders in the organizational system is an important task for cybersecurity, and existing information security tools and systems often need to be improved to mitigate the possible consequences of insider exposure. The scientific novelty of the reviewed study, according to the reviewer, consists in the conclusions that emails are an important attribute for detecting internal threats, as well as adapting machine learning methods to identify abnormal emails from employees and ensure the cybersecurity of organizations. The following sections are highlighted in the text of the article: Introduction, Existing approaches, Research Methodology, Experiments and results, Conclusion, Bibliography. The article provides a brief and succinct overview of available scientific papers on the issues discussed in the publication; reflects the main stages of the work done by the authors on data collection, their preliminary preparation for analysis, describes in an accessible form the machine learning platforms used, data processing algorithms and programming languages; shows the results of training on a test dataset. The text is illustrated with 2 tables and 4 figures, the presentation of the material is accompanied by 4 formulas. The bibliographic list includes 19 sources – scientific publications in Russian and English on the topic under consideration, to which the text contains targeted links, which confirms the existence of an appeal to opponents. To improve the publication, the authors are invited to adjust the title of the article, focusing not on machine learning, but on countering the insider threat to information security – in this version, the article will organically fit into the topic of the journal "Security Issues", since in the presented version the work looks closer to the IT sphere than to the field of security. For example, the following wording is possible: "Countering the insider threat to information security using machine learning methods." It should also be noted that the approaches discussed in the article have yet to be tested on actual real data, and not only on publicly available sets of them. The reviewed material corresponds to the direction of the journal "Security Issues", reflects the results of the work carried out by the authors, contains elements of scientific novelty and practical significance, may arouse interest among readers, and is recommended for publication taking into account the expressed wishes.
Link to this article
You can simply select and copy link from below text field.
|
|





