|
MAIN PAGE
> Back to contents
Security Issues
Reference:
Pleshakova E.S., Gataullin S.T., Osipov A.V., Romanova E.V., Samburov N.S.
Effective classification of natural language texts and determination of speech tonality using selected machine learning methods
// Security Issues.
2022. № 4.
P. 1-14.
DOI: 10.25136/2409-7543.2022.4.38658 EDN: UPWMCV URL: https://en.nbpublish.com/library_read_article.php?id=38658
Effective classification of natural language texts and determination of speech tonality using selected machine learning methods
Pleshakova Ekaterina Sergeevna
ORCID: 0000-0002-8806-1478
PhD in Technical Science
Associate Professor, Department of Information Security, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th Veshnyakovsky Ave., 12k2, building 2

|
espleshakova@fa.ru
|
|
 |
Other publications by this author
|
|
Gataullin Sergei Timurovich
PhD in Economics
Dean of "Digital Economy and Mass Communications" Department of the Moscow Technical University of Communications and Informatics; Leading Researcher of the Department of Information Security of the Financial University under the Government of the Russian Federation
8A Aviamotornaya str., Moscow, 111024, Russia
|
|
stgataullin@fa.ru
|
|
|
Other publications by this author
|
|
Osipov Aleksei Viktorovich
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 4th veshnyakovsky str., 4, building 2
|
|
avosipov@fa.ru
|
|
|
Other publications by this author
|
|
Romanova Ekaterina Vladimirovna
PhD in Physics and Mathematics
Associate Professor, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.
|
|
EkVRomanova@fa.ru
|
|
|
Other publications by this author
|
|
|
Samburov Nikolai Sergeevich
Student, Department of Data Analysis and Machine Learning, Financial University under the Government of the Russian Federation
125167, Russia, Moscow, 49/2 Leningradsky Ave.
|
|
ncsamburov@mail.ru
|
|
|
|
DOI: 10.25136/2409-7543.2022.4.38658
EDN: UPWMCV
Received:
23-08-2022
Published:
30-12-2022
Abstract:
Currently, a huge number of texts are being generated, and there is an urgent need to organize them in a certain structure in order to perform classification and correctly define categories. The authors consider in detail such aspects of the topic as the classification of texts in natural language and the definition of the tonality of the text in the social network Twitter. The use of social networks, in addition to numerous advantages, also carries a negative character, namely, users face numerous cyber threats, such as personal data leakage, cyberbullying, spam, fake news. The main task of the analysis of the tonality of the text is to determine the emotional fullness and coloring, which will reveal the negatively colored tonality of speech. Emotional coloring or mood are purely individual traits and thus carry potential as identification tools. The main purpose of natural language text classification is to extract information from the text and use processes such as search, classification using machine learning methods. The authors separately selected and compared the following models: logistic regression, multilayer perceptron, random forest, naive Bayesian method, K-nearest neighbor method, decision tree and stochastic gradient descent. Then we tested and analyzed these methods with each other. The experimental conclusion shows that the use of TF-IDF scoring for text vectorization does not always improve the quality of the model, or it does it for individual metrics, as a result of which the indicator of the remaining metrics for a particular model decreases. The best method to accomplish the purpose of the work is Stochastic gradient descent.
Keywords:
artificial intelligence, machine learning, neural networks, personal data, cybercrimes, social network, cyber threats, classification of texts, the tonality of the text, spam
This article is automatically translated.
You can find original text of the article here.
The article was prepared as part of the state assignment of the Government of the Russian Federation to the Financial University for 2022 on the topic "Models and methods of text recognition in anti-telephone fraud systems" (VTK-GZ-PI-30-2022). Text classification has gained huge popularity in recent years, and has found application of this technology in various applications, such as the classification of emotions from text, spam classification and many others. With the advent of social networks, people have become more likely to express their emotions through their activities on social networks. People convey their emotions through social media posts, such as comments on their own or someone else's posts, reviews, blogs. The machine can process different types of data [1-3]. For example, services such as YouTube and TikTok work with photos and videos. Algorithms analyze your actions: both the topic and the direction of the video, the language, and how fully you watch the video are taken into account. The machine analyzes this data, and based on it recommends new videos that you are likely to like. Also, with the help of other signs, the machine can be trained to recognize a person in a video or photo. Such technologies are widely used around the world to ensure security: the prevention or investigation of crimes. All modern music streaming services, such as Spotify and Yandex.Music, which contain a "Recommendations" section, work on a similar principle. The machine analyzes the mood of the song, its genre, language and popularity. Many manufacturers of goods and services also use machine learning to collect and analyze feedback from their customers in order to further improve their product and stand out favorably from competitors. In such cases, the text of the reviews is processed, as well as other factors, such as whether a refund has been issued. One of the other applications of machine learning in text classification tasks is machine translation of natural languages [4-5]. In this work, the training of models was carried out on the text data of publications on the social network Twitter on the topic “COVID-19”. In this paper, the authors consider the problem of determining the tonality of the text. The main task of analyzing the tonality of the text is to determine the emotional fullness and coloring. To perform text classification tasks, there are the most suitable methods: logistic regression, multilayer perceptron, random forest, naive Bayesian method, K-nearest neighbor method, decision tree, stochastic gradient descent. Models are evaluated using various indicators - reliability of predictions, accuracy, completeness and F-score. Also, one of the tasks is to use technologies to improve the quality of models. Text classification The task of determining the tonality of the text is identical to other tasks of text classification. The machine analyzes the text, highlighting keywords, their semantic load and significance for determining mood, on the basis of which it makes its conclusion. The tonality of texts can be divided into three main groups - negative, positive and neutral, where the latter means the absence of emotional coloring in the text. To solve this problem, the data set "Coronavirus tweets NLP" was selected [6-7]. Since the machine recognizes keywords when classifying texts, it would be advisable to create a "word cloud" for the texts of all publications of the dataset. In order to correctly train the model and obtain clean results, it is necessary to clear the text of unnecessary characters and meaningless words. The first step is to remove punctuation marks, numbers, "@" and "#" characters, as well as the HTTP protocol text. A significant part of meaningless words are so-called "stop words". After cleaning the processed text, we compile a dictionary for further research. 1. Tokenization of the text 
Creating a "word cloud" for the cleared data: 
Fig. 2. "Word cloud" for the cleared data To simplify further classification, classes from the "Mood" column are replaced with numeric values from 1 to 5, where 1 is "Extremely negative" and 5 is "Extremely positive": Model training. Sample separation and text vectorization.The next task is to encode words in sentences with numerical representations. To do this, you can create a dictionary of all the unique words that occur in the dataset and associate each of the words in the sentence with this dictionary. In this case, each sentence should be presented as a list, the length of which will be equal to the size of the dictionary of unique words (53553 words in our case), and each index of such a list will store how many times a word occurs in this sentence. This method is called a "Bag of words" [8]. The bag of words model (BoW model) is a shortened and simplified representation of a text document from selected parts of the text based on certain criteria, such as the frequency of words. The size of the training sample was 32925 elements, the test sample was 8232. Logistic regression
One of the simplest and most common tools in text classification is logistic regression. Logistic regression falls under the algorithm of controlled classification [9]. This algorithm has gained importance recently, and its use has increased significantly. The training time of the model was 16.6 seconds. Metrics are poor, 57% accuracy of predictions suggests that the model was wrong in almost half of the cases. According to the results obtained, we see that the worst indicators are when predicting positive and negative publications. 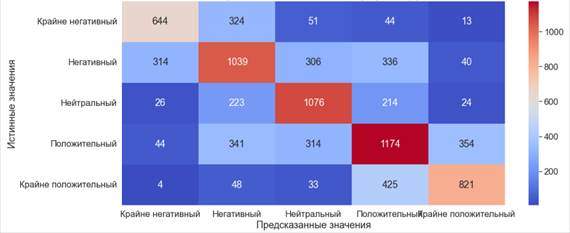
Fig. 3. Error matrix. Logistic regression (5) The result obtained arose due to the fact that logistic regression is difficult to work in cases where the target contains more than 2 values. Let's try to reduce the number of classes and compare the results. To do this, we will combine "Extremely positive" and "Positive" publications under one label. We will do the same operation with negative publications and set the gradation from 0 to 2, where 0 is negative reviews, and 2 is positive. After changing the labels, the class distribution looks like this: 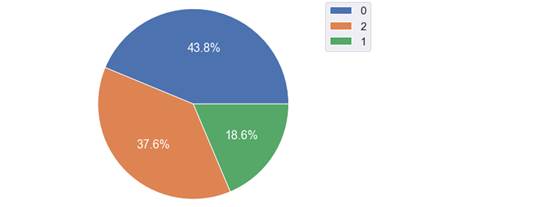
Fig. 4. Distribution of classes after combining labels After the merger, we will conduct re-training. The results have improved significantly (accuracy of ?80% is considered a good indicator). The training time was 9.7 seconds. A detailed report showed that the model predicts positive publications best. 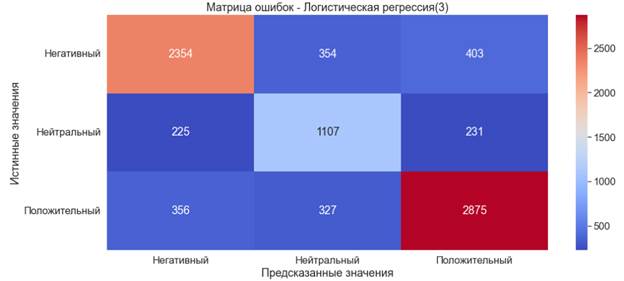
Fig. 5. Error matrix. Logistic regression (3) Since the classification of texts is considered in the work, some words may be more important for the distribution of the text into one or another category. This problem is solved by the TF-IDF (Term Frequency – Inverse Document Frequency) method for text vectorization. The TF-IDF technique is usually used to extract features and to define terms that occur repeatedly in the text. TF-IDF does not reappear in general for each collection of documents. The selection of related keywords and the definition of the method are used to encode these keywords in supervised machine learning. These keywords can have a huge impact on the ability of classification methods to extract the best pattern. This method determines how often a word occurs in various documents and, based on this, assigns significance to the words for classification [10]. To do this, apply TfidfVectorizer on top of an already existing "Bag of words": Now, for example, let's build a new logistic regression and compare the results. The result shows that the indicators increased slightly, by about 1%. When training further models, both the usual "Bag of Words" and with the use of TF-IDF will be used. Multilayer Perceptronthe most traditional type of neural network architecture is the multilayer perceptron network (MLP). This is a class of artificial neural networks with direct communication, consisting of at least three layers of nodes: an input layer, a hidden layer and an output layer. A perceptron is a block that receives one or more input data (values of independent variables in the model), subjects each input to a unique linear mathematical transformation, including multiplication by a weighting parameter, summation of weighted input data, addition of an offset parameter, and processing. the resulting value of the activation function, which then serves as the output of the perceptron block [11]. The MLPClassifier classifier is used to train the multilayer perceptron model: The training time of the model is 3 minutes and 30 seconds. · Accuracy ?79% is a good indicator· Precision ?79% is a good indicator· Recall ?79% is a good indicator· F-score ?79% is a good indicator. 6. Error matrix. 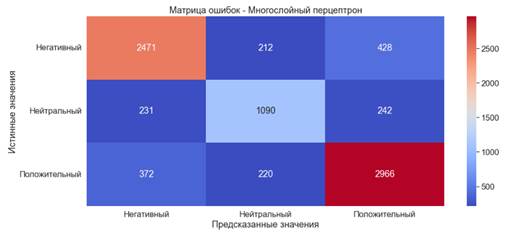
Multilayer perceptron with a "Bag of words" With the use of TF-IDF The model was trained in 3 minutes 53 seconds. · Accuracy ?78% is a good indicator· Precision ?78% is a good indicator
· Recall ?78% is a good indicator· F-score ?78% is a good indicator Indicators fell by about 1% compared to the results of a multilayer perceptron with a "Bag of words" Fig. 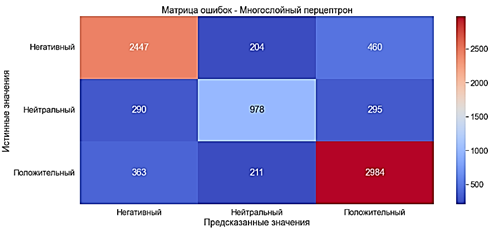
7. Error matrix. Multilayer perceptron with TF-IDF Random Forest A random forest works with decision trees that are used to classify a new object from an input vector. This algorithm builds a large number of decision trees because they work together. Decision trees act as pillars in this algorithm. A random forest is defined as a group of decision trees whose nodes are determined at the preprocessing stage [12]. After building several trees, the best feature is selected from a random subset of features. To train a Random Forest model, the RandomForestClassifier classifier is used. The model was trained in 51 seconds· Accuracy ?75% is a good indicator· Precision ?75% is a good indicator· Recall ?75% is a good indicator· F-score ?75% is a good indicator. 8. Error matrix. 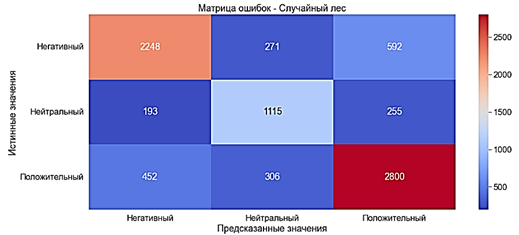
Random forest with a "Bag of words" With TF-IDF, the model learned in 46 seconds. · Accuracy ?20% is a very bad indicator· Precision ?80% is a good indicator· Recall ?20% is a very bad indicator· F-score ?8% is a very bad indicator The use of TF-IDF has degraded the quality of the model so much that it cannot be used to perform classification tasks. 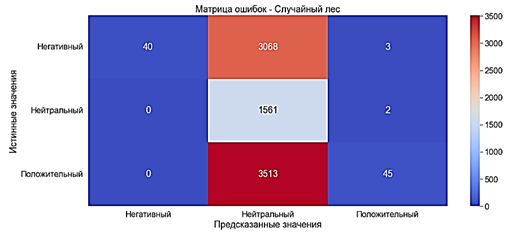
Fig. 9. Error matrix. Random forest with TF-IDFMODEL defined almost all documents as "Neutral". Naive Bayesian method The naive Bayes algorithm is used for pattern recognition and classification, which fall under various variants of image classifiers for basic probability and likelihood [13]. The MultinominalNB classifier is used to train the Naive Bayesian model. The model was trained in 0.009 seconds. · Accuracy ?67% - average· Precision ?69% - average· Recall ?67% - average· F-score ?65% - average
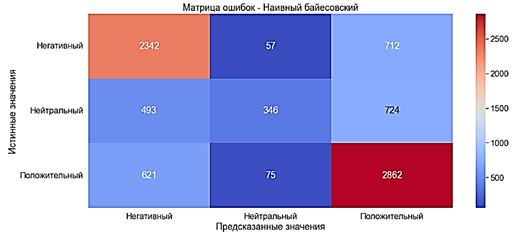
Fig. 10. The error matrix. Naive Bayesian method with the "Bag of words" WITH TF-IDF The model was studied in 0.01 second. · Accuracy of ?63% - average · Precision of ?70% - average · Recall ?63% - average · F-score ?56% - bad record Performance deteriorated by approximately 4% compared with the Naive Bayes model with the "Bag of words". The greatest losses in the metric F-score – 9% 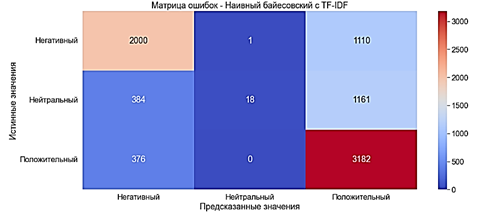
Fig. 11. The error matrix. Naive Bayes with TF-IDF The method of K-nearest neighbors This algorithm focuses on the conservation of similar things closer to each other. This model works with class labels and feature vectors in the data set [14]. KNN stores all cases, and helps to classify new cases, with the help of measures of similarity. In K-nearest neighbors the text is represented using a spatial vector, which is denoted by S = S ( T1 , W1 ; T2 , W2, ... Tn , Wn ). For any text using the training text is calculated similarity, and selected texts with the greatest similarity. Finally, the classes are determined on the basis of the K neighbors. To train the model by the method of K-nearest neighbors classifier is used KNeighborsClassifier: The model was trained for 0,003 sec. · Accuracy of ?31% - very poor indicator · Precision of ?65% of the average · Recall ?31% - very poor indicator · F-score ?29% is a very poor indicator 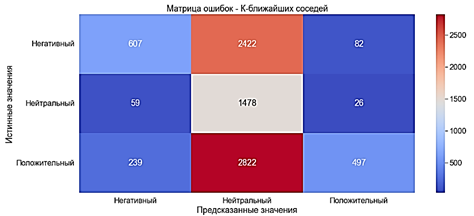
Fig. 12. The error matrix. The method of K-nearest neighbors with a "Bag of words" CTF-IDF Due to some characteristics of the classifier in this case, we can't build a model by the method of K-nearest neighbors using TF-IDF. Decision tree The decision tree generates a set of rules that can be used to categorize data according to a set of attributes and their classes. To train the model by the method of decision Tree classifier is used DecisionTreeClassifier. The model was trained for 8 seconds. · Accuracy of ?70% - average · Precision of ?70% - average · Recall ?70% - average · F-score ?70% - average 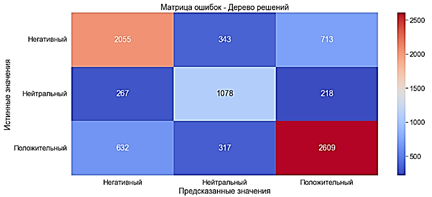
Fig. 13. The error matrix. The decision tree with the "Bag of words" WITH TF-IDF The model was trained for 9 seconds. · Accuracy ?61% - average · Precision of ?62% - average
· Recall ?62% - average· F-score ?62% - average The indicators deteriorated by about 8% compared to the Decision Tree model with a "Bag of words". 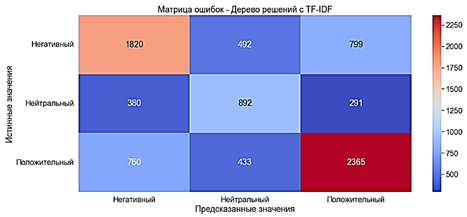
Fig. 14. Error matrix. Decision Tree with TF-IDF Stochastic Gradient Descent Algorithm is very similar to traditional gradient descent. However, it only calculates the loss derivative of one random data point, not all data points (hence the name, stochastic). This makes the algorithm much faster than gradient descent. The SGDClassifier classifier is used to train the model by stochastic gradient descent. The model was trained in 0.226 seconds. · Accuracy ?82% is a very good indicator· Precision ?82% is a very good indicator· Recall ?82% is a very good indicator· F-score ?82% is a very good indicator. 15. Error matrix. 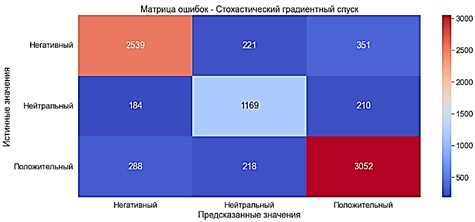
Stochastic gradient descent with a "Bag of words" With TF-IDF The training of the model was 0.127 seconds. · Accuracy ?77% is a good indicator· Precision ?77% is a good indicator· Recall ?77% is a good indicator· F-score ?76% is a good indicator The indicators deteriorated by about 5% compared to the stochastic gradient descent model with a "Bag of words". Conclusion This article provides an extensive and systematic overview of various machine learning methods for determining the tonality of speech from the point of view of natural language processing. Actions such as: data set analysis, creation of descriptive graphs and statistical information, data set preprocessing, feature extraction and text vectorization, model construction, improvement of the quality of constructed models are implemented. Below is a table that contains summary information about the results of training models using the methods discussed in the paper: 
Fig. 16. Comparative table of models Color designations in the table: 1. Green color – improvement of the indicator of the model or a separate metric. 2. Red color - deterioration of the indicator of the model or a separate metric. 3. The blue color is the model with the best indicators.
References
1. Perera R., Nand P. Recent advances in natural language generation: A survey and classification of the empirical literature //Computing and Informatics. – 2017. – Т. 36. – №. 1. – С. 1-32.
2. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
3. Sun F. et al. Pre-processing online financial text for sentiment classification: A natural language processing approach //2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr). – IEEE, 2014. – С. 122-129.
4. Carstens L., Toni F. Using argumentation to improve classification in natural language problems //ACM Transactions on Internet Technology (TOIT). – 2017. – Т. 17. – №. 3. – С. 1-23.
5. Mahesh K., Nirenburg S. Semantic classification for practical natural language processing //Proc. Sixth ASIS SIG/CR Classification Research Workshop: An Interdisciplinary Meeting. – 1995. – С. 116-139.
6. Romanov A., Lomotin K., Kozlova E. Application of natural language processing algorithms to the task of automatic classification of Russian scientific texts //Data Science Journal. – 2019. – Т. 18. – №. 1.
7. Young I. J. B., Luz S., Lone N. A systematic review of natural language processing for classification tasks in the field of incident reporting and adverse event analysis //International journal of medical informatics. – 2019. – Т. 132. – С. 103971.
8. Dien T. T., Loc B. H., Thai-Nghe N. Article classification using natural language processing and machine learning //2019 International Conference on Advanced Computing and Applications (ACOMP). – IEEE, 2019. – С. 78-84.
9. Pranckevičius T., Marcinkevičius V. Comparison of naive bayes, random forest, decision tree, support vector machines, and logistic regression classifiers for text reviews classification //Baltic Journal of Modern Computing. – 2017. – Т. 5. – №. 2. – С. 221.
10. Chen P. H. Zafar, H., Galperin-Aizenberg, M., & Cook, T. . Integrating natural language processing and machine learning algorithms to categorize oncologic response in radiology reports //Journal of digital imaging. – 2018. – Т. 31. – №. 2. – С. 178-184.
11. Heo, T. S., Kim, Y. S., Choi, J. M., Jeong, Y. S., Seo, S. Y., Lee, J. H., Kim, C. (2020). Prediction of stroke outcome using natural language processing-based machine learning of radiology report of brain MRI. Journal of personalized medicine, 10(4), 286.
12. Shah, K., Patel, H., Sanghvi, D., & Shah, M. (2020). A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augmented Human Research, 5(1), 1-16.
13. Kim, S. B., Han, K. S., Rim, H. C., & Myaeng, S. H. (2006). Some effective techniques for naive bayes text classification. IEEE transactions on knowledge and data engineering, 18(11), 1457-1466.
14. Dien, T. T., Loc, B. H., & Thai-Nghe, N. (2019, November). Article classification using natural language processing and machine learning. In 2019 International Conference on Advanced Computing and Applications (ACOMP) (pp. 78-84). IEEE.
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The reviewed article is devoted to the application of machine learning methods to solve the problem of classifying texts in natural language and determining the tonality of speech. The research methodology is based on the study of literature sources on the topic of the work, the use of methods of logistic regression, multilayer perceptron, random forest, naive Bayesian method, K-nearest neighbor method, decision trees, stochastic gradient descent. The authors of the article rightly associate the relevance of the study with the possibility and necessity of using machine learning methods to classify texts, recognize threats, ensure security, prevent or investigate crimes. The scientific novelty of the presented research, according to the reviewer, lies in the application of machine learning methods to determine the tonality of text, emotional fullness and coloring of speech in order to ensure safety. The authors have identified the following structural sections in the article: Introduction, Text classification, Sample separation and text vectorization, Logistic regression, Multilayer Perceptron, Random Forest, Naive Bayesian method, K-nearest neighbor method, Decision Tree, Stochastic gradient descent, Conclusion, Bibliography. Based on the use of machine learning methods, the authors analyze the text, highlighting keywords, their semantic load and significance for determining mood, on the basis of which they conclude that the tonality of the text belongs to one of three groups - negative, positive and neutral (with the absence of emotional coloring in the text). The data set "Coronavirus tweets NLP" was used as a training sample of the problem, which was cleared of unnecessary characters (punctuation marks, numbers, and various symbols), "stop words" and meaningless words for correct training of the model. The bibliographic list includes 14 names of sources in English, to which the text contains address links indicating the presence of an appeal to opponents in the publication. The advantages of the reviewed article include the use by the authors of a graphical method of presenting materials, successfully illustrated with numerous drawings. The reviewed article is not without flaws. Firstly, the use of the word "selected" in the title of the work seems unnecessary, since it does not carry any additional information for the reader. Secondly, in Conclusion, a comparative table of machine learning models is presented, but no generalizations are made about the expediency of using them to determine the tonality of the text, nothing is said about testing the machine learning model on materials from other datasets and the practical significance of the research results for strengthening security. Thirdly, Figures 5-15 are tables rather than figures, as evidenced by their name: "Error Matrix". Fourth, it is appropriate to expand the list of references through publications in Russian, given the increased number of scientific articles on machine learning in domestic publications, which should also be reflected in the presentation of the degree of knowledge of the problem. The topic of the article is relevant, the material corresponds to the topic of the journal "Security Issues", may arouse interest among readers and is recommended for publication after the elimination of comments.
Link to this article
You can simply select and copy link from below text field.
|
|





