|
MAIN PAGE
> Back to contents
Cybernetics and programming
Reference:
Rudometkin V.А.
Monitoring and troubleshooting in distributed high-load systems
// Cybernetics and programming.
2020. № 2.
P. 1-6.
DOI: 10.25136/2644-5522.2020.2.32996 URL: https://en.nbpublish.com/library_read_article.php?id=32996
Monitoring and troubleshooting in distributed high-load systems
Rudometkin Vasilii Andreevich
Expert in the development of services "Geolocation", MTS
109382, Russia, Moskva oblast', g. Moscow, ul. Krasnodonskaya, 36, kv. 120

|
vasiliy.rudometkin@gmail.com
|
|
 |
|
DOI: 10.25136/2644-5522.2020.2.32996
Received:
26-05-2020
Published:
10-08-2020
Abstract:
The subject of the research is the problem of monitoring and troubleshooting in distributed high-load systems. The most common mistakes in design and development, methods of their forecasting and solutions are described. In this article, the author describes the most popular tools that are currently used in the development of high-load systems and the main mistakes when working with them from a developer's point of view.This article describes a set of tools, the implementation of which can significantly reduce the time spent searching for vulnerabilities, describes the difficulties in choosing a set of metrics technologies - ELK / EFK, describes their advantages and disadvantages. The analogs of the tools used are analyzed in detail. The main conclusions in the work are:- the need to develop the infrastructure for monitoring the system from the beginning of the project development, due to which it is possible to correct the high complexity of the project at the stage of its development.- it is necessary to use the most popular tools for which there is a large amount of information in open sources, for example, on the Internet. This approach will reduce the time spent on fixing errors that can be caused by a specific set of tools.- the company needs not to save on highly qualified personnel, which in the future will save a lot of time on fixing problems, reduce the time for developing new functionality and allow spending a minimum of time to support and test the already developed functionality.- when analyzing problems, it is worth paying attention to public resources in which other companies, most likely, have already solved similar problems. For example, the Facebook company has been dealing with the monitoring problem for a long time and has developed a large number of tools to solve this problem. They also collect a large number of system records for analyzing the behavior of the system under any circumstances.
Keywords:
monitoring, hightload system, metrics, ELK, EKF, white box, black box, testing, quality control, architecture
This article written in Russian. You can find original text of the article here
.
В настоящее время информационные системы становятся все крупнее и сложнее, включают в себя большое количество инфраструктурных компонентов, такие как сервера очередей, базы данных и сами сервисы, количества которых может достигать десятков штук, а если рассматривать масштабируемые системы, то количество инстансов сервисов может достигать нескольких тысяч. В такой системе поиск ошибок ставится проблемой, если не уделить должного внимания инструментам мониторинга.
Мониторинг высоконагруженной системы является основной обязанностью оперативных групп и зачастую разработчиков. На сегодня существует множество стратегий и инструментов для мониторинга серверов, сбора важных данных и реагирования на ошибки и изменения условий в различных средах. Однако по мере развития программных методов и проектов инфраструктуры мониторинг должен адаптироваться для решения новых задач и освещения относительно незнакомой территории.
В статье «Актуальность современных систем удаленного мониторинга вычислительных ресурсов»1 Сильнов Д.С. рассмотрел проблему мониторинга с точки зрения активного и пассивного мониторинга и подробно описывает необходимые компоненты системы для мониторинга, но рассматривает инструменты для мониторинга поверхностно и опирается на ОС Windows, которое накладывает ограничения на проектирование системы.
Рассмотрим подробнее основные направления в мониторинге:
White-box мониторинг основан на показателях, отображаемых внутренними компонентами системы, включая журналы, метрики профилирования виртуальной машины Java или обработчика HTTP, которые генерируют внутреннюю статистику.
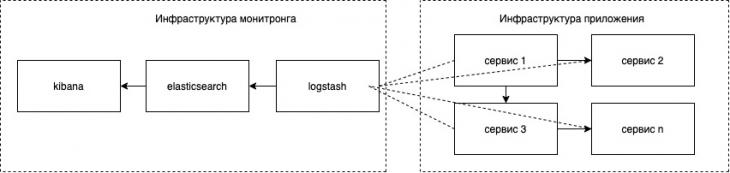
Рис 1. White-box мониторинг2
На рисунке 1 изображена схема взаимодействия компонентов для White-box мониторинга. Инфраструктура для мониторинга является отдельно стоящей для приложения, чтобы не создавать дополнительную нагрузку. Все компоненты системы отправляют метрики в logstash, где они форматируются и отправляются в elasticksearch. При построении архитектуры мониторинга, любой компонент может быть заменен на аналог.
Для снижения нагрузки на систему мониторинга рекомендуется взаимодействовать с ней при помощи сервера очередей, например kafka. Такое взаимодействие позволит быстро освобождать сервис и снимет требования ко времени обработки метрик.
Наиболее важные характеристики, за которыми необходимо следить - сеть, загрузка ОЗУ и ЦП. Такие параметры могут предоставлять сами сервисы, но не стоит собирать метрики слишком часто, так как это создает дополнительную и довольно высокую нагрузку на сервис.
Одним из самых первых требований к системе является логирование - отслеживание цепочек происходящих событий с целью поиска неисправностей. Но события нужно складывать и обрабатывать и для этого существует большое количество инструментов, таких как Sphinx, Algolia и другие, но наиболее популярным является elasticksearch. Это поисковые инструменты, которые хранят, обрабатывают и предоставляют API к данным в системе.
Для того что бы добавить информацию в инструменты хранения используются инструменты первичной обработки данных от компонентов системы, такие как Fluentd, Graphite и другие, но одним из самых популярных является logstash, который способен быстро обрабатывать большое количество информации.
Для отображения данных в системе хранения используются инструменты, которые позволяют легко интегрироваться с системой хранения и быстро выдавать результаты, такие как Graylog, Graphite, но одним из самым популярных является Kibana.
При построении системы мониторинга стоит выбрать между EFK (elastic + fluentDb + Kibana) и ELK (elastic + logstash + Kibana)3, так как эти два подхода являются наиболее популярными в настоящее время и информации по ним сейчас очень много, поэтому создание хорошей системы мониторинга не займет много времени, но позволит быстро находить и устранять проблемы.
Но не стоит забывать о Black-box мониторинге, который должен в режиме реального времени отображать работоспособность системы. Данный мониторинг является первый стадией для анализа проблемы, поэтому необходимо выводить на него как можно больше информации по сервисам, сетевому взаимодействию компонентов, количестве пользователей и их активностях.
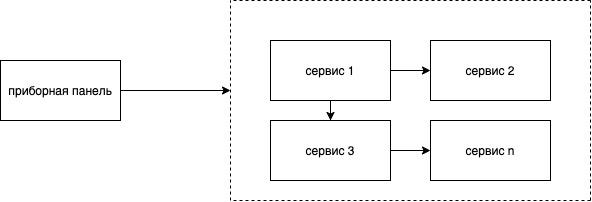
Рис. 2 Black-box мониторинг
На рисунке 2 изображена схема Black-box мониторинга, на которой приборная панель отображает состояние системы в целом и показывает актуальный статус системы. Необходимый набор метрик для данного мониторинга является - сетевая нагрузка на сервисы, количество подключений к инстансам сервиса, количество инстансов каждого сервиса и история изменения метрик.
Такие системы развиваются довольно давно, поэтому их большое количество. Одни из самых популярных это Graphite, Zabbix, Grafana. В большинстве случаев приборные панели являются сложными решениями, поэтому позволяют интегрировать в себя дополнительные расширения, которые могут нести полезную информацию в зависимости от требований, которые выставлены системе Black-box мониторинга.
В период активного развития микросервисной архитектуры, одной из важных метрик при работе с высоконагруженной системе становится нагрузка сети - необходимо следить за маршрутизацией трафика в системе, отслеживать количество подключений к инстансам сервиса - в случае если количество соединений к инстансам достигает предела, то новые запросы не получат доступа к сервиса, а клиент получит ошибку. Одним из инструментов для маршрутизации трафика является Istio, который позволяет строит график взаимодействия между сервисами, отслеживая “горячие” места и предоставляя график с компонентами, на случай если один из сервисов откажет.
В высоконагруженной системе с большим количеством сервисов проблема отслеживания запроса с целью оптимизации является сложной задачей, а зачастую невыполнимой стандартными инструментами. Для решения это проблемы используются технологии, которые позволяют отслеживать запрос - OpenTracing. Это решение добавляет метаинформацию при взаимодействии сервисов, в которой содержится сквозной идентификатор. В качестве более удобного решения можно использовать технологии, основанные на OpenTracing, например Spring Boot Sleuth совместно с Zipkin. Такое решение позволяется отслеживать маршрутизацию запросов, предоставляет подробную информацию по нему (рис. 3).

Рис. 3. Архитектура Spring Boot Sleuth совместно с Zipkin.
На рисунке 3 изображена архитектура мониторинга запросов при использовании Spring Boot Sleuth совместно с Zipkin:
- В каждом сервисе на кластере присутствует модуль Spring Boot Sleuth
- И используя http или сервер очередей данные запросов попадают в Zipkin(collector)
- Collector складывает данные в базу данных
- При обращении пользователя в Zipkin UI, query server формирует запросы к базе данные, что позволяет отображать необходимые данные пользователю
Еще одним важным аспектом является срок хранения метрик. Некоторые компании, например, Facebook хранят хронику событий вечно. Эти требования зависят от размера системы и используемости метрик. Например, метрики по сети необходимо хранить для статистики и обработки инцидентов, если серверное оборудование поставляет другая компания, а большое количество хроник событий позволяет отследить основные пользовательские сценарии и время их выполнения, что в дальнейшем может служить для оптимизации трафика и упрощения процессов для пользователя, что приведет к быстрым бизнес процессам системы и положительно скажется на клиенте.
Наиболее эффективные технологии применены на проекте МТС ПОИСК4. В настоящий момент на обработку поступает около 5000 событий в секунду, что создает довольно высокую нагрузку на систему, поэтому проблема мониторинга крайне остро стояла на проекте. Старое решение на ELK стеке создавало высокую нагрузку на систему мониторинга и зачастую блокировала работу приложения. Замена Logstash на Kafka позволило решить эту проблему.
Так как обработка каждого события в системе затрагивает большое количество компонентов системы, то в случае некорректного поведения в системе найти неисправность было невозможно. Внедрение Spring Boot Sleuth позволила сократить время на поиск до десяти минут.
Анализируя выборы технологий ведущих IT компаний мира, то можно сделать несколько вывод об используемых технологиях мониторинга - в большинстве случаев компании используют ELK или, реже, EFK стек технологий. Большинство технологий для мониторинга разработаны крупнейшими компаниями, такими как, Facebook5.
Таким образом, благодаря правильно разработанному инструменту мониторинга высоконагруженных систем получится появляется возможность оперативного выявления несоответствия системы заявленным требованиям, что позволяет оперативно исправлять необходимые компоненты системы, а большой набор анализируемых данных позволяет анализировать работу системы со стороны клиента, что способствует правильному развитию системы с точки зрения надежности и качества функционирования и захвата большего сегмента рынка, удовлетворяя потребности большего количества пользователей.
References
1. Sil'nov D.S. Aktual'nost' sovremennykh sistem udalennogo monitoringa vychislitel'nykh resursov [TEKST]/Sil'nov D.S. - Sankt-Peterburg, izvestiya RGPU im. a.i. Gertsena, 2020, 55-59
2. Elektronnyi resurs, Sistemnoe administrirovanie, rezhim dostupa https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
3. Petrov V.V. Sbor, Analiz i filtratsiya bol'shikh dannykh s pomoshch'yu steka ELK [TEKST]/ Petrov V.V. - Colloquium-journal, 2019 - Ukraina, Golaya Pristan', Colloquium-journal, 2020
https://cyberleninka.ru/article/n/sbor-filtratsiya-i-analiz-bolshih-dannyh-s-pomoschyu-steka-elk/viewer
4. Elektronnyi resurs, ofitsial'nyi sait MTS POISK, rezhim dostupa https://poisk.mts.ru/
5. Elektronnyi resurs, ofitsial'nyi sait github - razrabotki Facebook, rezhim dostupa https://github.com/facebook
6. Elektronnyi resurs, zhurnal pol'zovatel'skikh publikatsii, stat'ya monitoringa v Google https://habr.com/ru/post/484246/
7. Elektronnyi resurs, ofitsial'nyi sait Zabbix, rezhim dostupa https://www.zabbix.com/ru/
8. Elektronnyi resurs, ofitsial'nyi sait Kibana, rezhim dostupa https://www.elastic.co/kibana
9. Elektronnyi resurs, ofitsial'nyi sait ElasticSearch, rezhim dostupa https://www.elastic.co/
10. Elektronnyi resurs, ofitsial'nyi sait Istio, rezhim dostupa https://istio.io
11. Metody i sredstva metamonitoringa raspredelennykh vychislitel'nykh sred [TEKST]/Sidorov I.A., Novopashin A.P., Oparin G.A., Skorov V.V. - Chelyabinsk, Vestnik YuUrG,2014,1-39
Link to this article
You can simply select and copy link from below text field.
|
|





