|
MAIN PAGE
> Back to contents
Litera
Reference:
Beliaeva T.R.
Frequency and distribution of the units of general scientific (academic) lexicon as the markers of disciplinary affiliation of a discourse
// Litera.
2021. № 6.
P. 164-175.
DOI: 10.25136/2409-8698.2021.6.35902 URL: https://en.nbpublish.com/library_read_article.php?id=35902
Frequency and distribution of the units of general scientific (academic) lexicon as the markers of disciplinary affiliation of a discourse
Beliaeva Tatiana Rafaelovna
External Doctoral Candidate, the faculty of Foreign Languages and Regional Studies, M. V. Lomonosov Moscow State University
119991, Russia, g. Moscow, ul. Leninskie Gory, 1, str. 13-14, of. 213

|
t.r.belyaeva@gmail.com
|
|
 |
|
DOI: 10.25136/2409-8698.2021.6.35902
Received:
08-06-2021
Published:
15-06-2021
Abstract:
This article is dedicated to a corpus-based research of functionality of the units of general scientific (academic) lexicon in various types of disciplinary discourse, the purpose of which lies in verification of a hypothesis on a special function of the academic lexicon to indicate disciplinary affiliation of the scientific text. In the era of increasing mathematization and digitalization of scientific knowledge, corpus linguistics becomes a paramount instrument of empirical research aimed at acquisition of knowledge on the language through quantitative and qualitative analysis of compilations of texts, the scope and subject of which can be set in accordance with the specific objectives of the scholar. Special role in corpus-based research is assigned to the methods of statistical analysis for effective processing of the obtained quantitative data on linguistic realias, thereby considering linguistic research equivalent to the research of exact and natural sciences by degree of verification. The article describes the fragment of comprehensive research on functionality of the general scientific lexicon, which using the statistical method of correlation analysis on the example of more than 100 general scientific words (nouns, verbs, adjectives, and adverbs) established correlation between frequency and distribution of the units of general scientific lexicon and the type of disciplinary discourse. The scientific novelty lies in the holistic approach towards analyzing the characteristic features of distribution of the frequency of general scientific lexical units in 8 types of disciplinary discourse, as well as in in application of the methods of descriptive and mathematical statistics that demonstrate that academic lexicon same as terminological lexicon may serve as marker of disciplinary affiliation of the discourse.
Keywords:
general scientific vocabulary, academic vocabulary, corpus linguistics, quantitative analysis, qualitative analysis, statistics, frequency, distribution, correlation analysis, Spearman’s rank correlation
This article written in Russian. You can find original text of the article here
.
Математизация и компьютеризация научного знания, являющиеся отличительными характеристиками современного этапа развития постнеклассической науки, радикальным образом изменили как средства, так и методы получения и оценки результатов исследований. Методы прикладной математики (математической статистики, IT технологий и т.д.), наряду с естественными науками, получили широкое применение и в различных областях гуманитарного знания. Одним из свидетельств подобного положения дел является растущая популярность корпусной лингвистики, обусловленная, в первую очередь, новой методологией, позволяющей применять реляционно-статистический подход к описанию языковых реалий. Методы корпусной лингвистики не только позволяют создавать коллекции текстов любых объемов и тематической или профильной специфики, но и получать достоверные, верифицированные квалитативные и квантитативные данные о языке благодаря постоянно совершенствуемым поисковым и статистическим инструментам, инкорпорированным в корпусные менеджеры (corpus manager) – функциональные оболочки лингвистических корпусов.
Статистически значимые базы данных позволяют собирать конкретную лингвистическую информацию [10: 30], объективируя и уточняя наблюдения о языке, часть из которых было бы сложно верифицировать без применения корпусных технологий. Применение методов математической статистики для оценки полученных данных дает возможность обнаруживать закономерности и тенденции в развитии языка, которые без получения четких математических моделей сложных языковых реалий могли бы остаться незамеченными. [5: 5]. В частности, методы корпусной лингвистики позволяют выявить и проанализировать особенности функционирования в речи лексических единиц, включая тонкие семантические нюансы, влияющие на парадигматику и синтагматику их взаимодействия с другими единицами языка.
Так, корпусные исследования последних десятилетий изменили представление о функционировании единиц общенаучной (академической) лексики, интерес к которой как в отечественной, так и в западной лингвистике не ослабевает со второй половины ХХ века и прежде всего обусловлен нуждами преподавания английского языка специальности на нелингвистических факультетах высших учебных заведений [2]. До появления методов корпусной лингвистики ученые полагали, что единицы общенаучной лексики, являющиеся одним из компонентов лексики любого научного текста наравне с терминологией и словами общего языка и занимающие при этом положение «переходного звена от общего языка к языку науки» [4: 150], функционируют одинаково в любом научном дискурсе, независимо от его дисциплинарной принадлежности. Однако системное сопоставительное исследование функционирования и семантики общенаучных слов в дискурсах различных типов позволило установить обусловленные типом дискурса различия как в количественном (частотность и распределение), так и в качественном (коллокации и семантика) отношениях [12]. Результаты исследования позволили выдвинуть гипотезу о том, что функционирование общенаучной лексики находится в тесной взаимосвязи с типом академического (научного) дискурса, а лексические единицы данного слоя не только не являются «общими» для всех его разновидностей, а, напротив, могут рассматриваться в качестве дискурс-специфических признаков текста, маркируя его дисциплинарную принадлежность.
В качестве материала и инструмента исследования был использован Академический подкорпус Корпуса современного американского английского языка (The Corpus of Contemporary American English, далее – СОСА), созданного американским лингвистом Марком Дэвисом [7]. СОСА представляет собой прекрасный пример Big Data (большого массива языковых данных) в лингвистике и является в настоящий момент единственным сбалансированным корпусом американского варианта английского языка. Обновленный в марте 2020 г., СОСА содержит более миллиарда словоупотреблений и охватывает широкий спектр разнообразных языковых регистров, каждый из которых представлен отдельным подкорпусом: Spoken language, Fiction, Popular magazines, Newspapers, Academic texts, TV and Movies subtitles, Blogs и other web pages.
Академический подкорпус, в свою очередь, структурно разбит на 9 подкорпусов: 8 из них представляют дисциплины естественнонаучного и гуманитарного циклов (History, Education, Social Science, Law, Humanities, Philosophy, Science and Technology и Medicine), а подкорпус Business and Finance составляют в основном статьи из финансовых разделов газет, что не соответствует концепции научного стиля речи и явилось причиной для исключения данного подкорпуса из настоящего исследования. В отличие от Business and Finance, остальные 8 подкорпусов базируются на материалах авторитетных американских научных журналов, о чем свидетельствуют данные о включенных в подкорпусы материалах, приведенные создателями Academic Vocabulary List в статье, описывающей принципы и методы его формирования [9: 313].
До масштабной реструктуризации и модификации функционала СОСА в 2020 г., частью которой в том числе стала интеграция в него Академического подкорпуса, последний был представлен отдельным ресурсом, Word and Phrase (https://www.wordandphrase.info), с функциональной оболочкой (корпусным менеджером), позволяющей сопоставлять функционирование общенаучной лексики по всем представленным в Академическом подкорпусе направлениям научного знания.
Для того чтобы проверить, существует ли взаимосвязь между частотностью общенаучной лексики и дисциплинарной принадлежностью дискурса, необходимо было произвести выборку академических слов таким образом, чтобы она была качественно и количественно репрезентативна. Поскольку состав каждого лексического слоя (общеупотребительного, академического и терминологического) не является строго очерченными, критерием для включения общенаучных лексических единиц в выборку послужила их регистрация в двух наиболее известных и широко применяемых списках академических слов – Academic Word List Эверил Коксхед [6] и Academic Vocabulary List Ди Гарднера и Марка Дэвиса [9]. Стоит подчеркнуть, что оба списка были составлены на основании статистических критериев (частотности, дисперсии и т.д.), референсные значения которых в этих списках различны. Таким образом, регистрация слов в обоих списках дает возможность составить репрезентативную выборку лексических единиц, принадлежащих слою лексики, объем которого, как и состав, определить не представляется возможным в силу онтологии самого языка, а единственными бесспорными характеристиками формирующих данный слой лексических компонентов можно считать лишь многозначность семантики и высокую частотность в произведениях научной речи.
Таким образом, был получен список из 101 общенаучного слова, почти в равных долях состоящий из существительных (accuracy, acquisition, analysis, approach, aspect, capability, capacity, category, criterion, device, hypothesis, innovation, mechanism, method, mode, paradigm, phenomenon, precision, principle, procedure, process, scope, structure, technique, theory), глаголов (analyze, achieve, acquire, attain, clarify conduct conclude; coordinate; deduce define demonstrate denote display, evolve, exhibit, identify, illustrate, imply, indicate, induce, infer, interpret, obtain, process, specify), прилагательных (adaptive, accessible, accurate, analogous, appropriate, available, comprehensive, concurrent, considerable, conventional, corresponding, distinctive, equivalent, global, negative, overall, positive, potential, precise, primary, principal, significant, similar, specific, traditional, unique, virtual) и наречий (accurately, appreciably, approximately, conceptually, consequently, considerably, consistently, distinctively, dynamically, hence, intensively, likewise, nevertheless, nonetheless, potentially, precisely, previously, radically, reliably, sequentially, significantly, similarly, specifically, successively).
Первый этап исследования заключался в сборе данных о частотном распределении (distribution) академических слов выборки, для чего была собрана информация о частотности каждой лексической единицы во всех рассматриваемых дискурсах, затем систематизированная в таблицу. Поскольку корпусы имеют разный объем, абсолютные частоты были пересчитаны в относительные (instances per million – ipm), что дало четкую картину распределения частот лексических единиц выборки по 8 рассматриваемым дисциплинарным дискурсам. В Таблице 1 приводится фрагмент данных для всей выборки (по 2 академических слова на каждую часть речи): каждая колонка представляет дисциплинарный подкорпус (дисциплинарный дискурс), а строки таблицы дают информацию о частотах, которые соответствующие общенаучные слова демонстрируют в каждом из дискурсов.
Таблица 1. Фрагмент сводной таблицы распределения частот общенаучных лексических единиц (существительных, глаголов, прилагательных и наречий) в различных видах научного дискурса
|
academic
words
|
His[1]
Ipm
|
Hum
Ipm
|
Phil
Ipm
|
Law
Ipm
|
Edu
Ipm
|
Soc
Ipm
|
Sci
Ipm
|
Med
Ipm
|
|
analysis
|
220,2
|
271,6
|
290,5
|
264,4
|
880,8
|
779,8
|
397,8
|
615,5
|
|
category
|
105,0
|
160,6
|
124,1
|
106,0
|
336,5
|
306,5
|
122,8
|
152,1
|
|
process
|
25,5
|
31,2
|
35,1
|
30,9
|
98,4
|
38,0
|
128,3
|
61,5
|
|
display
|
54,1
|
126,1
|
51,6
|
31,3
|
86,7
|
79,4
|
110,5
|
55,4
|
|
overall
|
66,3
|
56,4
|
56,3
|
67,1
|
195,5
|
147,4
|
113,9
|
155,2
|
|
available
|
156,0
|
187,8
|
146,5
|
199,6
|
326,9
|
257,5
|
435,6
|
432,8
|
|
previously
|
70,1
|
66,0
|
58,3
|
61,5
|
105,6
|
102,1
|
88,0
|
119,9
|
|
similarly
|
77,9
|
92,7
|
71,9
|
91,7
|
106,1
|
104,8
|
65,9
|
53,3
|
При анализе частотных данных, представленных в Таблице 1 (в оригинальном исследовании в таблицу были сведены данные для всей выборки – 101 общенаучного слова), обращают на себя внимание близкие по значению частоты, которые демонстрируют общенаучные лексические единицы в дисциплинах, относящихся к одному виду дискурса, что позволяет наметить некоторые тенденции в соотношении значений лексических частот между дисциплинами гуманитарного дискурса, который представлен историческими и гуманитарными науками, юриспруденцией и философией, а также между междисциплинарными науками (социологией и педагогикой). Так, значения частот существительного analysis в гуманитарных дискурсах варьируются в диапазоне от 220,2 ipm до 290,5 ipm, при этом разница между частотами в History, Humanities, Philosophy и Law не превышает 16%, а в междисциплинарных Education и Social Science различие частотных значений analysis составляет около 11%, но разница между наибольшим значением в гуманитарных дискурсах (Philosophy – 290,5 ipm) и наименьшим в междисциплинарных (Social Science – 779,8 ipm) превышает 3,5 раза. Такая же картина наблюдается в целом ряде других случаев, например, с частотным распределением прилагательного overall: разница между частотами overall в гуманитарных дискурсах едва превышает 9%, между частотами в социологическом и педагогическом дискурсах она составляет 24%, при этом наибольшее значение частотности в гуманитарных дискурсах (Law – 67,1 ipm) более, чем в 2 раза меньше, чем наименьшее частотное значение в мультидисциплинарных (Social Science – 147,4 ipm).
Представленный в настоящей работе фрагмент данных дает лишь общее представление о том, что частотность общенаучных (академических) слов носит дискурс-специфический характер, а ее распределение маркирует вид дисциплинарного дискурса: для проверки гипотезы потребовался комплексный анализ всех частотных значений (808 количественных показателей – 8 частотных рядов, представляющих частоты для каждого из 101 общенаучного слова в 8 подкорпусах) в их системных отношениях.
С точки зрения статистики корпусные исследования можно охарактеризовать как поиск переменных и анализ взаимосвязей между ними. В настоящем исследовании в качестве переменных выступают представленные в каждом подкорпусе ряды лексических частот, построение математической модели связей между которыми позволит установить, есть ли связь между частотностью и дистрибуцией общенаучных слов и видом дискурса.
С этой целью было решено применить один из методов математической статистики – ранговый корреляционный анализ Спирмена, универсальный непараметрический метод, получивший широкое применение не только в технических, естественных и точных науках, но и в социологии, психологии, корпусной лингвистике и даже литературоведении. Так, применение метода ранговой корреляции Спирмена для сопоставления частотных словарей языка русских поэтов разных эпох и литературных направлений позволило В.С. Баевскому установить «некоторый «общепоэтический» слой лексики, общий всем поэтам от Грибоедова, Пушкина, Лермонтова до Межирова, Вознесенского и Высоцкого» [1, 98], а также выявить лексику, типичную для представителей одного направления или, наоборот, характерную для поэтического языка отдельных авторов.
По аналогии с приведенным выше исследованием применение корреляционного анализа Спирмена позволит выстроить модель связи между рядами частотных данных, представленных во всех рассматриваемых дискурсах: значения коэффициентов парной корреляции между дискурсами будут указывать на степень связи между ними, предоставляя тем самым данные для верификации гипотезы.
Представленные во всех исследуемых дискурсах частотные ряды были ранжированы (по принятой в статистике традиции большему значению был присвоен меньший ранг [3, 175]), а затем были вычислены коэффициенты ранговой корреляция Спирмена для всех пар исследуемых дискурсов по формуле rs 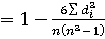 ,где rs – коэффициент ранговой корреляции Спирмена, ,где rs – коэффициент ранговой корреляции Спирмена, 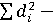 сумма квадратов разностей рангов, а n - число парных наблюдений. сумма квадратов разностей рангов, а n - число парных наблюдений.
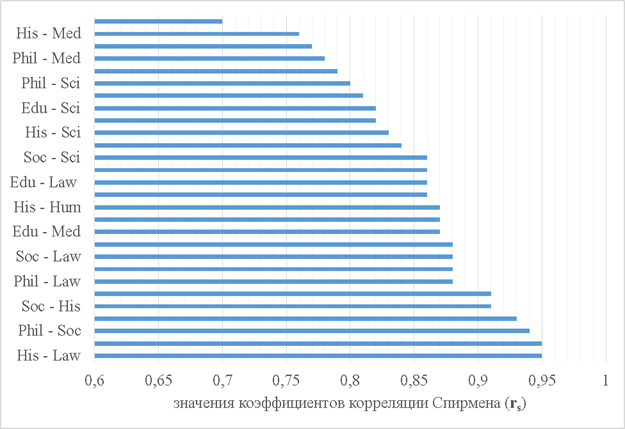
Результаты корреляционного анализа, который был проведен при помощи инструментов Excel, были обобщены в корреляционную матрицу (Таблица 2), а также представлены в виде гистограммы, где значения коэффициентов парной ранговой корреляции Спирмена, характеризующие силу связи между дискурсами, изображены графически, что позволяет визуализировать системные отношения между всеми видами рассматриваемых дискурсов. (Рисунок 1).
Таблица 2. Матрица коэффициентов парной ранговой корреляции Спирмена (rs) для всех исследуемых дисциплинарных дискурсов
|
|
His
|
Hum
|
Phil
|
Law
|
Edu
|
Soc
|
Sci
|
Med
|
|
His
|
|
|
|
|
|
|
|
|
|
Hum
|
0,87
|
|
|
|
|
|
|
|
|
Phil
|
0,91
|
0,93
|
|
|
|
|
|
|
|
Law
|
0,95
|
0,82
|
0,88
|
|
|
|
|
|
|
Edu
|
0,87
|
0,81
|
0,86
|
0,86
|
|
|
|
|
|
Soc
|
0,91
|
0,88
|
0,94
|
0,88
|
0,95
|
|
|
|
|
Sci
|
0,83
|
0,79
|
0,80
|
0,84
|
0,82
|
0,86
|
|
|
|
Med
|
0,76
|
0,70
|
0,78
|
0,77
|
0,87
|
0,88
|
0,86
|
|
Значения коэффициентов корреляции Спирмена могут варьироваться в диапазоне от -1 (свидетельство наличия обратной связи) до +1 (наличие прямой корреляционной связи), а также могут равняться 0, если связь между наблюдаемыми признаками отсутствует. Чем ближе значение коэффициента корреляции к 1, тем сильнее связь между признаками.
Рисунок 1. Гистограмма значений коэффициентов парной ранговой корреляции Спирмена для всех исследуемых дискурсов
Для интерпретации значений коэффициентов корреляции между величинами в исследованиях (в том числе в гуманитарных науках) используется шкала Чеддока [3, 190], предлагающая достаточно тонкую градацию силы корреляционной связи (Таблица 3).
Таблица 3. Референсная таблица Чеддока для интерпретации значений коэффициентов корреляции
|
Коэффициент корреляции
|
Характеристика силы связи
|
|
rs < 0,1
|
cвязь практически отсутствует
|
|
0,1 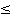 rs rs 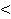 0,3 0,3
|
cлабая связь
|
|
0,3 rs 0,5
|
умеренная связь
|
|
0,5 rs 0,7
|
cвязь средней силы
|
|
0,7 rs 0,9
|
cильная связь
|
|
0,9 rs 1
|
очень сильная связь
|
Согласно градации Чеддока анализируемые дискурсы находятся в «сильной» или «очень сильной связи», что лишь подтверждает их принадлежность к одному регистру речи – научному, отличительной характеристикой которого является в том числе высокая частотность единиц общенаучной лексики. Однако референсные значения, предложенные Чеддоком, не позволяют в полной мере интерпретировать данные, полученные в рамках настоящего исследования. Так как в статистике не существует единых теоретических оснований для оценки данных и допустимым является любой формальный алгоритм, удовлетворяющий определенным требованиям, было решено рассчитать новые интервалы градации, использовав часто применяемую в описательной статистике стратегию равной ширины диапазонов, которая, в частности, может строиться на расчетах значений среднего арифметического [3, 175]. Таким образом, была получена новая градация (Таблица 4), позволяющая произвести анализ данных сообразно поставленной цели исследования – проверки гипотезы о наличии связи между распределением частотности общенаучных слов и принадлежностью научного текста к определенному виду дисциплинарного дискурса.
Таблица 4. Референсная таблица для интерпретации значений коэффициентов корреляции между исследуемыми дискурсами
|
Коэффициент корреляции
|
Характеристика силы связи
|
|
0,70 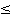 rs 0,82 rs 0,82
|
cлабая связь
|
|
0,82 rs 0,85
|
умеренная связь
|
|
0,85 rs 0,88
|
cильная связь
|
|
0,88 rs 1,00
|
очень сильная связь
|
Анализ данных попарной корреляции между рядами частот общенаучных слов выборки в каждом из исследуемых дисциплинарных дискурсов (Таблица 5) в большинстве случаев подтвердил выдвинутую гипотезу.
Таблица 5. Сила связи между исследуемыми дискурсами
|
пары сопоставляемых дискурсов
(расположены в порядке убывания силы связи)
|
значения коэффициентов корреляции
Спирмена (rs)
|
характеристика силы связи
|
|
History – Law
Social Science – Eduсation
Social Science – Philosophy
Humanities – Philosophy
Social Science – History
History – Philosophy
Philosophy – Law
Social Science – Humanities
Social Science – Law
Social Science – Medicine
|
0,95
0,95
0,94
0,93
0,91
0,91
0,88
0,88
0,88
0,88
|
очень сильная связь
|
|
Eduсation – Medicine
History – Eduсation
History – Humanities
Medicine – Science & Technology
Eduсation – Law
Philosophy – Eduсation
Social Science – Science & Technology
|
0,87
0,87
0,87
0,86
0,86
0,86
0,86
|
cильная связь
|
|
Law – Science & Technology
History – Science & Technology
Humanities – Law
Eduсation – Science & Technology
|
0,84
0,83
0,82
0,82
|
умеренная связь
|
|
Humanities – Education
Philosophy – Science & Technology
Humanities – Science & Technology
Philosophy – Medicine
Law – Medicine
History – Medicine
Humanities – Medicine
|
0,81
0,80
0,79
0,78
0,77
0,76
0,70
|
cлабая связь
|
Так, «слабая связь» прослеживается между всеми дискурсами гуманитарного цикла и медицинским дискурсом. В «слабой связи» состоят также философский и гуманитарный дискурсы с научно-техническим дискурсом, c которым, в свою очередь, юридический и исторический дискурсы находятся в «умеренной связи» (rs Law-Sci = 0,84 и rs His-Sci = 0,83 соответственно).
В самой сильной корреляции состоит большинство гуманитарных наук: «очень сильная связь» обнаруживается между историческим и юридическим дискурсами, историческим и философским дискурсами, гуманитарным (подкорпус Humanities) и философским дискурсами, а также философским и юридическим дискурсами. «Очень сильную связь» демонстрируют между собой и междисциплинарные социологический и педагогический дискурсы, при этом каждый из данных дискурсов состоит в «очень сильной» или «сильной» связях с дискурсами гуманитарного цикла. Медицинский и научно-технический дискурсы также, что было ожидаемо, находятся в «сильной связи».
Обобщая результаты анализа системы связей между дискурсами можно прийти к заключению, что дискурсы, условно относящиеся к общественно-гуманитарной области научного знания, находятся в «очень сильной» или «сильной связи» между собой, демонстрируя при этом «слабую» или «умеренную связь» с дисциплинами естественнонаучного цикла, которые, в свою очередь, состоят между собой в «сильной» или «очень сильной» связи. Данный вывод полностью совпадает с выдвинутой гипотезой о том, что распределение частотности общенаучных слов связано с принадлежностью текста к определенной разновидности дискурса. Однако неожиданно высокие значения коэффициентов корреляции между частотными рядами, представленными в социологическом и медицинском дискурсах (rs Soc-Med = 0,88), в педагогическом и медицинском дискурсах (rs Hum-Law = 0,87), характеризующими наличие между данными типами дискурсов «очень сильной связи», а также «сильная связь» между социологическим и научно-техническим дискурсом (rs Soc-Sci = 0,86), «умеренная связь» между гуманитарным и юридическим дискурсами (rs Edu-Med = 0,82) и «слабая» между гуманитарным и педагогическим (rs Hum-Edu = 0,81) поставили гипотезу исследования под сомнение.
Так как в рамках научного исследовательского подхода общепризнанной считается дихотомия количественного и качественного анализа – взаимодополняющих друг друга видов исследовательских процедур, было решено провести тщательный качественный анализ материалов, на которых базируются подкорпусы Education, Sociology, Humanities, Law, а также подкорпусы Science & Technology и Medicine. Подобный вид анализа в корпусной лингвистике осуществляется при помощи одного из инструментов корпусного менеджера – Конкорданса (Concordance), предоставляющего список всех контекстных употреблений искомого токена (в настоящем исследовании – общенаучного слова), как правило, снабженных ссылкой на источник.
Проведенный качественный анализ позволил установить, что значительная часть научных периодических изданий, послуживших источником текстового наполнения подкорпусов академической части COCA, не была включена в предоставленный авторами Academic Vocabulary List перечень [9: 313], по причинам нам не известным. Так, подкорпус Education содержит большой объем статей из научного журнала “Rural Special Education Quarterly”, посвященного вопросам специального образования и подготовки кадров для обучения людей с ограниченными возможностями: такой уклон подкорпуса Education в сферу медицины объясняет его «слабую связь» с гуманитарными дисциплинами. В материал социологического подкорпуса вошли статьи из журналов, чьи названия говорят сами за себя: “Journal of Social Psychology”, “Journal of Sex Research”, “Journal of Sport Behavior”, “Health & Social Work”, “Physical Educator”, “Journal of Drug Issues”. В юридическом подкорпусе превалируют статьи из журналов, посвященных юридическим аспектам налогообложения, международным исследованиям в области финансового регулирования, а также морского права и коммерции (“The Tax Lawer”, “Journal of Financial Regulation and Compliance”, “Journal of Maritime Law and Commerce”), что раскрывает причину наличия «умеренной связи» с гуманитарным дискурсом. И, наконец, подкорпус Science and Technology содержит тексты статей из журналов “Indian Journal of Orthopaedics”, “Asian Pacific Journal of Reproduction”, “Pharmaceutical Technology”, “Indian Dermatology Online Journal”, “BMC Bioinformatics”, “PLoS Computational Biology”, “Clinical Epigenetics” и т.д., что в контексте данного исследования «роднит» научно-технический дискурс с медицинским дискурсом, а также объясняет его «сильную связь» в том числе и с социологическим дискурсом.
Таким образом, качественный анализ материалов рассматриваемых подкорпусов не только не опроверг выдвинутую гипотезу, но, напротив, позволил убедительно ее подтвердить, поскольку неожиданно высокие коэффициенты корреляции между частотными рядами выборки академических слов в дискурсах разной дисциплинарной принадлежности «сигнализируют» о включении в дисциплинарные подкорпусы текстов, отличающихся своей ярко выраженной междисциплинарностью или вовсе принадлежностью к другой области научного знания.
Полученные результаты позволяют прийти к целому ряду выводов, наиболее важным из которых для настоящего исследования является фактически подтвержденное при помощи методов математической статистики наличие тесной взаимосвязи между распределением частот единиц общенаучной лексики и типом дисциплинарного дискурса: общенаучные (академические) слова, демонстрирующие высокую частотность в том или ином научном дискурсе, можно справедливо считать маркерами его дисциплинарной принадлежности не в меньшей степени, чем терминологические единицы лексики. Моделью тематики любого дисциплинарного дискурса является частотный словарь, верхняя область которого (самые частотные общенаучные единицы) раскрывают его онтологическую сущность. Данный вывод имеет важное значение для практики преподавания языка для специальных целей в высшей школе, акцентируя внимание на необходимости составления узко-дисциплинарных списков общенаучной лексики, что позволит оптимизировать процесс преподавания языка специальности и, как следствие, отчасти минимизировать усилия студентов, его осваивающих.
Результаты проведенного исследования также демонстрируют, что материал корпуса оказывает сильное влияние на лексическую вариативность [11], тем самым подталкивая к выводу о целесообразности создания специализированных, узко-дисциплинарных, узко-тематических корпусов, так как именно они являются наиболее репрезентативными, в частности, с точки зрения лингводидактики, педагогики, а также лексикографии.
Наконец, следует отметить, что в эпоху Big Data статистика, в качестве «науки о сборе и интерпретации данных» [8: vii], проникла практически во все области научного знания, меняя саму методику исследований и подходы к трактовке результатов научных наблюдений, а работы корпусных лингвистов последнего десятилетия лишь подтверждают, что гуманитарные науки не являются исключением.
[1] His – исторический дискурс, Hum – гуманитарный дискурс, Phil – философский дискурс, Law – юридический дискурс, Edu – педагогический дискурс, Soc – социологический, религиозный и психологический дискурсы, Sci – научно-технический дискурс, Med – медицинский дискурс.
References
1. Baevskii V.S. Lingvisticheskie, matematicheskie, semioticheskie i komp'yuternye modeli v istorii i teorii literatury. Moskva: Yazyki slavyanskoi kul'tury. 2001. – 338 c.
2. Polubichenko L.V. Obshchenauchnaya leksika v sostave nauchnogo diskursa: novye vozmozhnosti izucheniya. Sotsial'nye i gumanitarnye nauki na Dal'nem Vostoke. Khabarovsk; DVGUPS, tom 16, № 1, 2019. S. 26 – 30.
3. Samokhvalova E., Glotova M. Matematicheskaya obrabotka informatsii. 3-e izd., ispr. i dop. Uchebnik i praktikum dlya vuzov. Litres. 2021. – 301 c.
4. Tatarinov, V. A. Obshchee terminovedenie: Entsiklopedicheskii slovar' / V. A. Tatarinov. Rossiiskoe terminologicheskoe obshchestvo RossTerm. Moskva: Moskovskii Litsei, 2006. – 528 c.
5. Brezina, V. Statistics in Corpus Linguistics: A Practical Guide. Cambridge University Press, Kindle Edition, 2018.
6. Coxhead, A. A new academic word list. TESOL Quarterly, 34(2). 2000. – pp. 213–238.
7. Davies, M. Corpus of Contemporary American English (1990–2012). 2012. URL: http://corpus.byu.edu/coca/ (data obrashcheniya: 23.04.2021)
8. Diggle, P.J. & Chetwynd, A.G. Statistics and scientific method: an introduction for students and researchers. Oxford University Press. 2011. – 190 p.
9. Gardner, D., Davies, M. A New Academic Vocabulary List, Applied Linguistics, 35 (3). 2014. – pp. 305–327. URL: https://doi.org/10.1093/applin/amt015 (data obrashcheniya: 20.04.2021)
10. Kozera, I. The Method of Corpus Study – Advantages and Disadvantages (On the Example of Russian National Corpus). Studia Russologica, 11. 2018. – pp. 5 – 16 DOI 10.24917/16899911.11.2
11. Miller, D., Biber, D. Evaluating reliability in quantitative vocabulary studies: The influence of corpus design and composition. International Journal of Corpus Linguistics, Volume 20, Issue 1, 2015. pp. 30–53.
12. Polubichenko, L., Beliaeva, T. Discipline-conditioned choice and use of general scientific (academic) vocabulary. The European Proceedings of Social and Behavioural Sciences. 2020. – pp. 898–907 DOI: 10.15405/epsbs.2020.10.05.120
Link to this article
You can simply select and copy link from below text field.
|
|





