|
DOI: 10.25136/2409-8647.2020.1.32328
Received:
04-03-2020
Published:
09-04-2020
Abstract:
The object of this research is the methods of multi-criteria selection. The subject of this research is the problems of application of hierarchical method of randomized composite indicators in solving the problems of multi-criteria selection. It is noted that in gradual synthesis of composite indicators of the highest hierarchical level, it is impossible to obtain the exact values or assessment of probabilities of dominance of the compared objects. Structuring the exhaustive set of values of weight vector of hierarchy allows obtaining these probabilities, but such approach is applicable only in case of small number of characteristics of the compared objects. For solving this task, the author employs Monte Carlo method, consisting in formation of random sample from exhaustive set of weigh vector of hierarchy and sequential assessment of essential characteristics. The article suggests the procedure for assessing probability characteristics of randomized composite indicators. The author develops and presents the software written on the R platform for realization of this procedure. An example of comparison of the investment projects, when selection is based on the probability of dominance, rather than the composite indicators, is demonstrated.
Keywords:
multi-criteria selection, general indices method, randomization of uncertainty, Monte Carlo method, investments, decision making, decision support system, programming, R language, weight coefficients
This article written in Russian. You can find original text of the article here
.
Введение
Одной из важнейших задач, возникающих на практике перед инвесторами, является выбор наилучшего объекта инвестиций из возможных. В частном случае реальных инвестиций, инвестору необходимо выбрать наилучший инвестиционный проект из предложенных. Основой для оценки инвестиционной привлекательности обычно служит бизнес-план (технико-экономическое обоснование), составляемый инициатором проекта. В бизнес-плане содержится [4] информация о предлагаемых мероприятиях, о требуемых капиталовложениях, о связанных с реализацией проекта денежных потоках, о проектных рисках и т.д.
На основе этой информации могут быть определены различные показатели, с разных сторон характеризующие проект. На практике широко используются такие показатели экономической эффективности [2, 3], как чистая текущая стоимость (NPV), индекс рентабельности (PI), внутренняя норма доходности (IRR), срок окупаемости (PP или DPP) и другие. Методами имитационного моделирования и сценарного анализа могут быть оценены проектные риски, например, вероятность того, что проект окажется неэффективным (P(NPV<0)) [4]. Принимая решение, инвестор может учитывать состояние экономики страны или отрасли, надежность партнеров, совместно с которыми предлагается реализовать проект, и многое другое.
В настоящее время разработано множество систем показателей (примеры см. в [10, 11, 13]), позволяющих оценить инвестиционную привлекательность и отклонить неприемлемые проекты со слишком низкой доходностью или слишком высокими рисками. Однако крупный инвестор обычно не испытывает недостатка в предложениях, так что привлекательных проектов может оказаться больше, чем он сможет профинансировать. В частности, это могут разные варианты реализации одного проекта, отличающиеся некоторыми деталями. Из сказанного следует, что проблема сравнения инвестиционной привлекательности проектов является актуальной.
В данной статье предлагается использовать метод сводных показателей, который чаще всего используется для решения задач многокритериальной оптимизации [12]. В первой части статьи рассматриваются проблемы выбора весовых коэффициентов и описывается метод рандомизированных сводных показателей. Во второй части рассматриваются проблемы синтеза рандомизированных сводных показателей высших иерархических уровней, предлагается процедура оценивания их вероятностных характеристик по случайной выборке. В третьей части предложенная процедура применяется для решения задачи выбора наиболее привлекательного инвестиционного проекта.
1. Метод рандомизированных сводных показателей
При многокритериальном сравнении часто применяется метод сводных показателей [8, 12], суть которого заключается в получении на основе нескольких отдельных показателей q1, q2, ..., qn единого, сводного показателя Q с помощью некоторой синтезирующей функции. На практике часто используется линейная синтезирующая функция:
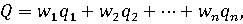
где w1, w2, ..., wn – весовые коэффициенты (веса), характеризирующие относительную важность отдельных показателей. Обычно предполагается, что веса удовлетворяют следующим условиям:
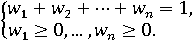
Весовые коэффициенты можно считать координатами вектора весовых коэффициентов (вектора весов, весового вектора) w=(w1, w2, ... , wn). Поскольку весовые коэффициенты безразмерны, сами отдельные показатели также должны быть безразмерны. Как правило, их получают на основе характеристик x1, x2, ..., xn объекта.
Если качество объекта и значение характеристики изменяются в одном направлении (чем выше значение характеристики xi, тем выше качество Q, и наоборот), можно использовать следующую формулу:
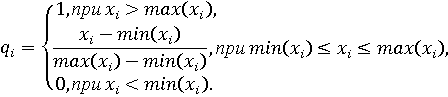
где max(xi), min(xi) – минимальное и максимальное значения характеристики xi. Это могут быть как значения, выбранные по всем сравниваемым объектам, так и некоторые априорно заданные граничные значения.
В том случае, если качество объекта и значение характеристики изменяются в противоположном направлении (чем ниже значение характеристики xi, тем выше качество Q, и наоборот), используется следующая формула:
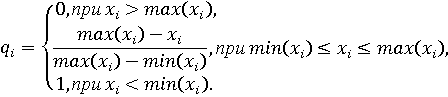
Рассчитанные таким образом значения отдельных показателей q1, q2, ..., qn для некоторого объекта можно считать координатами вектора отдельных показателей q=(q1, q2, ..., qn). Сводный показатель Q каждого объекта рассчитывается как скалярное произведение векторов w и q:
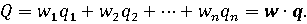
После расчета сводных показателей всех сравниваемых объектов выбор делается в пользу объекта с наибольшим значением сводного показателя.
Основная сложность применения метода сводных показателей на практике связана с тем фактом, что точные значения весовых коэффициентов (а следовательно, и точный вид синтезирующей функции) не известны. Обычно у лица, принимающего решение, имеется лишь неточная, нечисловая и неполная информация (ННН-информация) о весовых коэффициентах, представляющая собой систему неравенств, связывающих и ограничивающих значения весов [7, 8, 14].
Существует множество методов, позволяющих обработать экспертную ННН-информацию и получить конкретный вектор весовых коэффициентов (w1, w2, ... , wn). Возникающие в этом случае проблемы иллюстрирует пример, приведенный в [9].
Чтобы учесть неопределенность выбора весовых коэффициентов, может быть использована рандомизация - замена точно определенного вектора w=(w1, w2, ... , wn) на случайный вектор весов:
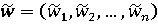
и следовательно, замена точно определенного сводного показателя Q=w1q1+...+wnqn на случайный - рандомизированный - сводный показатель:
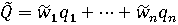
Множество возможных значений W случайного весового вектора представляет собой (n-1)-мерный симплекс в n-мерном пространстве:
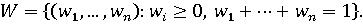
Если предположить, что значения координат отсчитываются с неким шагом h=1/k, то вместо непрерывного множества W можно рассматривать дискретное множество возможных значений WD, состоящее из конечного числа элементов N:
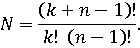
На рисунке 1 изображены непрерывное и дискретное множества возможных значений для случая n=3 и k=5.
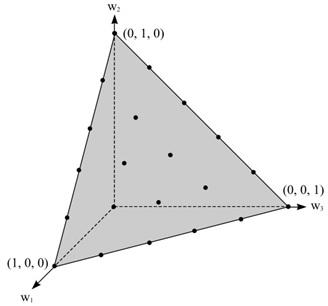
Рисунок 1. Непрерывное и дискретное множества возможных значений 3-мерного вектора весовых коэффициентов: W – треугольник, WD – множество точек.
После того как эксперт предоставит ННН-информацию I о весовых коэффициентах, множество возможных значений вектора весов W (или WD в дискретном случае) можно сократить до непрерывного множества допустимых значений W(I) (или дискретного WD(I), состоящего из N(I) элементов).
Например, пусть эксперт сообщил, что вес 1-го показателя не превосходит 0,5:
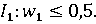
Также сообщил, что вес 2-го показателя превосходит вес 3-го показателя:
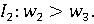
Объединив всю информацию, полученную от эксперта, получим:
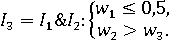
На рисунке 2 изображены непрерывное и дискретное множества допустимых значений относительно информации I1, I2, I3.
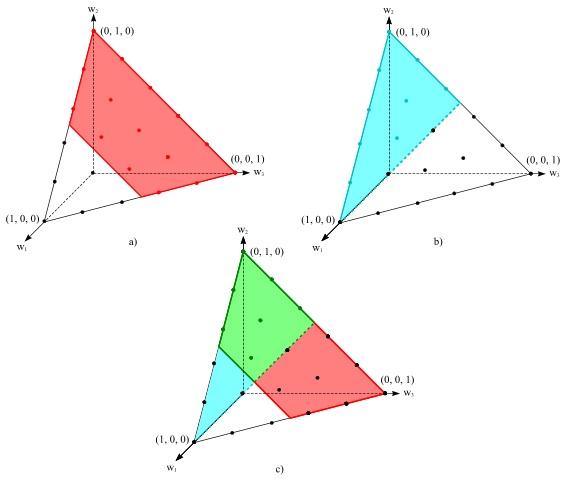
Рисунок 2. Непрерывное и дискретное множества допустимых значений вектора весов:
a) W(I1) – красная область (трапеция), WD(I1) – множество красных точек;
b) W(I2) – синяя область (треугольник), WD(I2) – множество синих точек;
c) W(I3) – зеленая область (трапеция), WD(I3) – множество зеленых точек.
Случайный вектор весов моделируется как многомерная равномерно распределенная на W(I) или WD(I) случайная величина, непрерывная или дискретная соответственно.
Для координат случайного вектора весов могут быть рассчитаны их вероятностные характеристики. Для упрощения вычислительных процедур предпочтительно использовать дискретные случайные векторы [14]. В этом случае математическое ожидание i-го весового коэффициента можно найти по формуле:
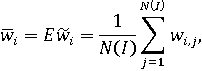
где wi,j - j-e допустимое значение i-го случайного весового коэффициента.
Точность полученной оценки можно охарактеризовать с помощью дисперсии i-го весового коэффициента:
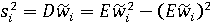 . .
Рандомизированный сводный показатель конкретного объекта (т.е. когда q=(q1, q2, ..., qn) – известный постоянный вектор) представляет собой функцию случайного весового вектора:
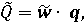
Для 3-мерного случая график функции Q=f(w), сопоставляющей значениям вектора весовых коэффициентов значения сводного показателя, представлен на рисунке 3.
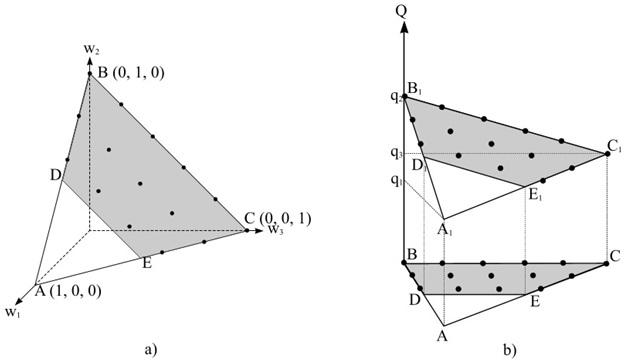
Рисунок 3. a) Непрерывное и дискретное множества допустимых векторов весовых коэффициентов, b) значения сводного показателя на множествах W(I) и WD(I)
Для рандомизированного сводного показателя также могут быть рассчитаны вероятностные характеристики. Математическое ожидание можно найти по формуле:
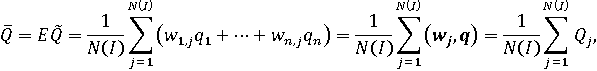
где wj –j-e допустимое значение вектора весовых коэффициентов, а Qj – соответствующее ему значение сводного показателя. Отсюда следует более простая формула:
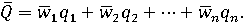
Дисперсия рандомизированного сводного показателя может быть найдена по формуле:
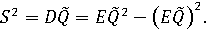
Рекомендуется [8] выбирать тот объект, для которого математическое ожидание рандомизированного сводного показателя является наибольшим. Как показано в [9], одних лишь математических ожиданий и дисперсий недостаточно для того, чтобы судить о надежности сделанных выводов, поэтому следует также рассчитывать вероятности попарного и абсолютного доминирования.
Поскольку случайный вектор весовых коэффициентов считается равномерно распределенным на множестве допустимых значений W(I) (или WD(I) в дискретном случае), эти вероятности легко найти, используя геометрическое (или классическое) определение вероятности [15].
Пусть сравниваются m объектов. Множества доминирования i-го объекта над j-м будем обозначим следующим образом:
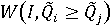
и
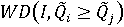
Множество доминирования - это подмножество непрерывного или дискретного множества допустимых значений вектора весовых коэффициентов, на котором выполняется соответствующее неравенство. Тогда вероятность доминирования i-го объекта над j-м объектом равна:
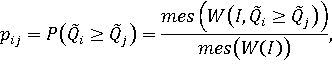
где mes(X) – (n-1)-мерный объем (мера) соответствующего множества X (сами множества предполагаются также (n-1)-мерными).
В случае дискретного множества допустимых весовых векторов формула имеет вид:

где вместо мер используются количества элементов в соответствующих дискретных множествах.
Ситуация для двух объектов, сравниваемых по 3-м показателям, проиллюстрирована на рисунке 4.
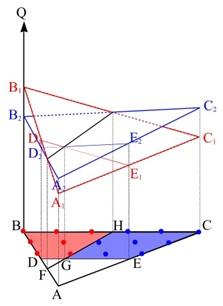
Рисунок 4. Множества доминирования 1-го объекта над 2-м (BHGD) и наоборот (HCEG).
Вероятности доминирования 1-го объекта над 2-м и наоборот могут быть определены как отношения площадей:
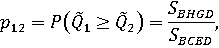
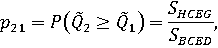
или как отношения количеств точек в соответствующих областях:
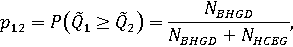
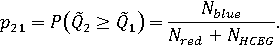
Назовем множеством абсолютного доминирования i-го объекта подмножество непрерывного или дискретного множества допустимых значений вектора весовых коэффициентов, на которых сводный показатель i-го объекта превышает или хотя бы не меньше сводных показателей всех остальных объектов. Тогда вероятность абсолютного доминирования i-го объекта в случае непрерывного множества допустимых весовых векторов:
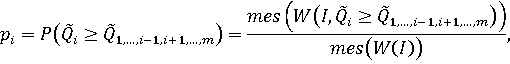
а в случае дискретного множества:
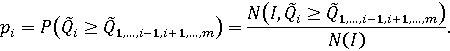
Вероятности абсолютного доминирования p1, p2, ..., pn каждого из m объектов можно интерпретировать как степень уверенности в том, что тот или иной объект является наилучшим и должен быть выбран. Сама процедура выбора также может быть рандомизирована и производиться не на основе математических ожиданий сводных показателей, а на основе вероятностей абсолютного доминирования: i-й объект выбирается с вероятностью pi.
Метод рандомизированных сводных показателей (МРСП) находит свое применение в самых разных областях [1, 5, 9, 16, 17]. В прикладных программах СППР APIS и ее ранней версии АСППИД-3W [8] неиерархический МРСП реализован в удобном для пользователя виде.
2. Иерархическая система синтеза сводного показателя
На практике сравниваемые объекты часто характеризуются большим числом n отдельных показателей. Уже при n>7 у экспертов возникают трудности [8], связанные с оценкой относительной важности отдельных показателей (т.е. с оценкой весов w1, w2, ... , wn). Для решения этой проблемы можно использовать иерархическую систему синтеза сводных показателей:
1) Исходные отдельные показатели подразделяются на несколько групп.
2) Для каждой группы строятся сводные показатели 1-го иерархического уровня, которые тоже могут быть подразделены на группы.
3) Для каждой группы сводных показателей 1-го уровня строятся сводные показатели 2-го уровня и т.д.
4) Результатом является единственный сводный показатель высшего иерархического уровня (итоговый сводный показатель).
В [8] рекомендуется процедура последовательного синтеза, которая заключается в следующем. После построения сводных показателей 1-го уровня рассчитываются их вероятностные характеристики. В качестве отдельных показателей при построении сводных показателей 2-го уровня используются не сами рандомизированные сводные показатели 1-го уровня, а только их математические ожидания (см. пример в [5]). Применение такой процедуры позволяет получить математическое ожидание и дисперсию итогового сводного показателя каждого из сравниваемых объектов, но найти вероятности доминирования таким способом невозможно.
Проблему, возникающую при процедуре последовательного получения сводных показателей высшего иерархического уровня, рассмотрим на простом примере. Пусть сравнивается 2 объекта по 4-м отдельным показателям, разделенным на 2 группы. Известно также, что в каждой группе первый показатель важнее, чем второй. Значения показателей приведены в таблице 1.
Таблица 1. Характеристики объектов A и B
|
Объект
|
Отдельные показатели
|
|
Группа 1. I1: (w11 > w12)
|
Группа 2. I2: (w21 > w22)
|
|
q11
|
q12
|
q21
|
q22
|
|
A
|
0,9
|
0,2
|
0,9
|
0,2
|
|
B
|
0,7
|
0,5
|
0,7
|
0,5
|
Рассматривая 1-ю группу показателей, получим математические ожидания сводных показателей (0,725 для объекта A, 0,65 для объекта B), а также вероятность доминирования объекта A над B по первому сводному показателю: p1AB=0,8. Эта ситуация наглядно представлена на рисунке 5.
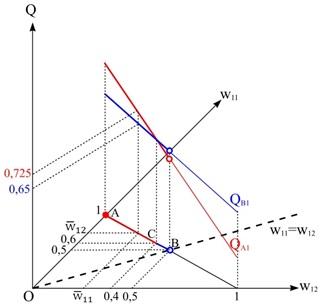
Рисунок 5. Сводные показатели 1-й группы характеристик для объектов A и B
Точно такие же значения будут получены и для сводных показателей 2-й группы. Из этого следует, что существуют такие наборы весовых коэффициентов, при которых предпочтительным будет объект B, а не A, например, если
(w11, w12)=(0,55, 0,45), (w21, w22)=(0,55, 0,45), а (wg1, wg2) - любой из множества допустимых векторов Wg(Ig). Это означает, что истинная вероятность попарного доминирования pAB<1.
Однако если строить итоговый сводный показатель на основе математических ожиданий сводных показателей 1-й и 2-й групп:
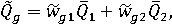
то при любом значении вектора (wg1, wg2) итоговый сводный показатель для объекта A будет больше, чем для объекта B, то есть будет получена вероятность попарного доминирования pAB=1, что не соответствует действительности. Таким образом, часть информации оказалась потерянной.
Проблему можно решить, если работать непосредственно с итоговыми рандомизированными сводными показателями объектов:
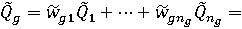
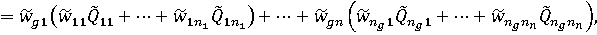
где Qg – итоговый сводный показатель (показатель высшего иерархического уровня), Qi, Qij и т.д. – сводные показатели нижних иерархических уровней, знак "~" означает, что соответствующая величина считается случайной (рандомизированной).
Назовем случайным вектором весов иерархии сводных показателей случайный вектор всех весовых коэффициентов, напрямую или опосредованно использующихся при расчете итогового сводного показателя:
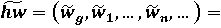
=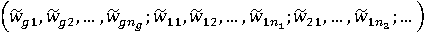 . .
Если предположить, что его компоненты независимы, то вектор весов иерархии будет иметь равномерное распределение на декартовом произведении всех множеств допустимых значений векторов весовых коэффициентов, использующихся для расчета сводных показателей всех иерархических уровней:
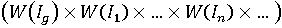
В дискретном случае это множество:
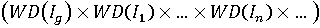
В этом случае число элементов множества значений вектора весов иерархии равно Nh=N(Ig)*N(I1)*...*N(In)*... и может быть весьма значительным. В случае небольшого числа отдельных показателей возможно рассчитать все значения итогового сводного показателя, соответствующие всем допустимым значениям вектора весов иерархии, как это было сделано в [9]. Будем называть эту процедуру процедурой формирования полного множества.
Если же отдельных показателей много, такой подход оказывается неприемлемым из-за большого числа Nh. В этом случае можно попытаться оценить вероятностные характеристики сводных показателей и вероятности доминирования на основе случайной выборки значений вектора весов иерархии:
1) Формируются множества WD(Ig), WD(I1), ...,WD(In) допустимых векторов для каждой группы показателей, как отдельных, так и сводных.
2) Случайно с равной вероятностью выбирается один элемент (вектор) из WD(Ig). Независимо от него выбирается один элемент из WD(I1) и т.д. Совокупность выбранных элементов и представляет собой выборочное значение вектора весов иерархии.
3) Процесс повторяется, пока количество элементов в выборке не достигнет заданного числа Nsample.
4) По выборочным значениям вектора весов иерархии рассчитываются выборочные значения итогового сводного показателя.
5) Математические ожидания рандомизированных сводных показателей и вероятности доминирования оцениваются по сформированной выборке.
Предложенную выше процедуру будем называть процедурой формирования случайной выборки. Она и будет применяться в настоящей статье.
3. Пример сравнения инвестиционных проектов
Используя предложенный подход, сравним инвестиционную привлекательность тех же проектов, что и в [9], чтобы иметь возможность сделать вывод о точности полученных оценок. Итоговый сводный показатель проектов строится на основе трех сводных показателей:
1) Показатель доходности, который строится на основе 4 частных показателей: чистая текущая стоимость – NPV, индекс рентабельности – PI, внутренняя норма доходности – IRR, срок окупаемости – DPP.
2) Показатель риска, который строится на основе 3-х частных показателей: срок достижения точки безубыточности – Tproj, вероятность неэффективности проекта – Prob, наличие опциона на выход из проекта – Opt.
3) Показатель репутации партнера, который строится на основе 3-х частных показателей: срок существования на рынке – Tcomp, доля партнера в проекте – Share, опыт успешных проектов – Exp.
Характеристики проектов приведены в таблице 2.
Таблица 2. Характеристики инвестиционных проектов.
|
Инвестиционный проект
|
A
|
B
|
C
|
|
Показатель доходности Q1
|
x11: NPV (↑), тыс.руб.
|
8544
|
11176
|
12089
|
|
x12: PI (↑)
|
1,17
|
1,22
|
1,26
|
|
x13: IRR (↑), %
|
24,8
|
31,4
|
34,1
|
|
x14: DPP (↓), лет
|
4,73
|
4,12
|
3,45
|
|
Показатель риска Q2
|
x21: Tproj (↓), мес.
|
7
|
9
|
4
|
|
x22: Prob (↓)
|
0,19
|
0,23
|
0,29
|
|
x23: Opt (↑)
|
1
|
1
|
0
|
|
Показатель репутации Q3
|
x31: Tcomp (↑), лет
|
18
|
7
|
15
|
|
x32: Share (↑), %
|
65
|
57
|
38
|
|
x33: Exp (↑), балл
|
4
|
5
|
3
|
Ограничения, налагаемые на весовые коэффициенты, используемые при построении сводных показателей, приведены в таблице 3.
Таблица 3. ННН-информация о весовых коэффициентах
|
Сводный показатель
|
Ограничения на весовые коэффициенты
|
|
Показатель доходности Q1
|
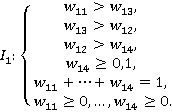
|
|
Показатель риска Q2
|
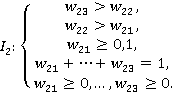
|
|
Показатель репутации Q3
|
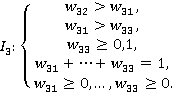
|
|
Итоговый сводный показатель Qg
|
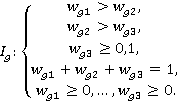
|
Полное множество значений весового вектора иерархии при шаге отсчета весовых коэффициентов 0,02 содержит Nh=N(Ig)*N(I1)*N(I2)*N(I3)=102*169*102*102 = 179 344 152 элемента. Для решения этой задачи была сформирована случайная выборка с повторением, размер которой был установлен равным Nsample = 10 000 000 элементов. Программный код на языке R приведен в приложении.
Точечные оценки математических ожиданий сводных показателей могут быть рассчитаны как средние арифметические:
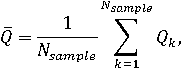
где Qk – значение в k-м наблюдении рандомизированного сводного показателя (любого иерархического уровня).
Чтобы составить представление о точности полученной оценки, можно воспользоваться неравенством Чебышева [6]. Рассчитанное среднее арифметическое является реализацией следующей случайной величины:
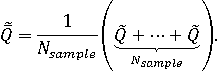
Ее характеристики:
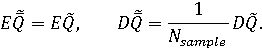
Неравенство Чебышева для этой случайной величины можно записать следующим образом:

поскольку рандомизированный сводный показатель принимает значения из отрезка [0, 1], так что его дисперсия не может превышать 1/4. Отсюда получаем, что с вероятностью не меньше (1-α) математическое ожидание принадлежит интервалу:
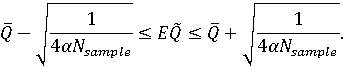
Отметим, что при выводе формулы никак не использовались особенности распределения рандомизированного сводного показателя, поэтому качество такой оценки будет невысоким. Впрочем, это можно компенсировать большим размером выборки.
Оценки математических ожиданий рандомизированных сводных показателей проектов, ≥95%-ные доверительные интервалы, а также точные значения математических ожиданий, полученные с помощью процедуры формирования полного множества [9], приведены в таблице 4.
Таблица 4. Оценки математических ожиданий рандомизированных сводных показателей
|
Проект
|
Выборочное среднее сводного показателя
|
≥95%-ный доверительный интервал
|
Истинное математическое ожидание
|
|
от
|
до
|
|
A
|
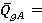
|
0,418608 |
0,417901 |
0,419316 |
0,418656
|
|
B
|
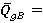
|
0,659813 |
0,659106 |
0,660520 |
0,659821
|
|
C
|
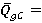
|
0,623037 |
0,622330 |
0,623744 |
0,622986
|
Точечные оценки вероятностей попарного и абсолютного доминирования могут быть найдены как относительные частоты:
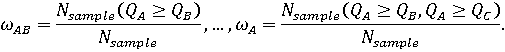
Доверительные интервалы для вероятностей попарного и абсолютного доминирования могут быть построены как (1-α)%-ные доверительные интервалы для вероятности биномиального распределения [6]:
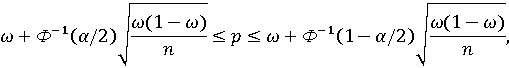
где p – истинное значение вероятности pA, pAB, pAC, pB, ...; ω – точечная оценка этой вероятности, т.е. частота ωA, ωAB, ωAC, ωB, ...; Ф-1(x) – обратная функция стандартного нормального распределения.
Точечные оценки вероятностей попарного доминирования, границы 95%-ных доверительных интервалов, а также точные значения этих вероятностей, полученные с помощью процедуры формирования полного множества [9], приведены в таблице 5.
Таблица 5. Оценки вероятностей попарного доминирования
|
Вероятность
попарного
доминирования
|
Точечная оценка
|
95%-ный доверительный
интервал
|
Истинное значение вероятности
|
|
от
|
до
|
|
P(A≥B)
|
ωAB
|
0,0000104
|
0,0000084
|
0,0000124 |
0,0000117
|
|
P(A≥C)
|
ωAC
|
0,1097451 |
0,1095514
|
0,1099388
|
0,1099237
|
|
P(B≥A)
|
ωBA
|
0,9999896
|
0,9999876 |
0,9999916 |
0,9999883
|
|
P(B≥C)
|
ωBC
|
0,6608644
|
0,6605710 |
0,6611578 |
0,6610635
|
|
P(C≥A)
|
ωCA
|
0,8902886
|
0,8900949 |
0,8904823 |
0,8901101
|
|
P(C≥B)
|
ωCB
|
0,3391356
|
0,3388422 |
0,3394290 |
0,3389365
|
Точечные оценки вероятностей абсолютного доминирования и границы 95%-ных доверительных интервалов приведены в таблице 6.
Таблица 6. Оценки вероятностей абсолютного доминирования
|
Вероятность абсолютного доминирования проекта
|
Точечная оценка
|
95%-ный доверительный
интервал
|
Истинное значение вероятности
|
|
от
|
до
|
|
A
|
ωA
|
0,0000104
|
0,0000084
|
0,0000124 |
0,0000117 |
|
B
|
ωB
|
0,6608544
|
0,6605610
|
0,6611478
|
0,6610525
|
|
C
|
ωC
|
0,3391352
|
0,3388418 |
0,3394286 |
0,3389358 |
Как следует из таблиц 4–6, полученные оценки соответствуют истинным значениям оцениваемых параметров.
Заключение
Используя оценки вероятностей абсолютного доминирования, можно сделать следующие выводы. Наиболее вероятно, что лучшим является проект B. Инвестировать же в проект A почти наверняка не следует. Выбрать проект можно случайным образом: с вероятностью 0,000 это будет проект A, с вероятностью 0,661 – проект B, а с вероятностью 0,339 – проект C.
Предложенная в статье процедура оценки вероятностей доминирования и математических ожиданий рандомизированных сводных показателей по случайной выборке позволяет получить результаты с высокой точностью, а ее выполнение занимает гораздо меньше времени, чем выполнение процедуры формирования полного множества. Поэтому можно рекомендовать ее применение даже в тех случаях, когда сравниваемые объекты обладают большим числом характеристик.
Приложение
Программа на языке R, реализующая предложенную в статье процедуру, приводится ниже.
|
1
|
qA <- vector(mode="numeric", length="10")
|
|
2
|
qB <- vector(mode="numeric", length="10")
|
|
3
|
qC <- vector(mode="numeric", length="10")
|
|
4
|
Ch <- c("NPV", "PI", "IRR", "DPP", "Tproj", "Prob", "Opt", "Tcomp", "Share", "Exp")
|
|
5
|
names(qA) <- Ch; names(qB) <- Ch; names(qC) <- Ch
|
|
6
|
# Задаются значения характеристик проектов A, B и C
|
|
7
|
xA <- c(8544 , 1.17, 24.8, 4.73, 7, 0.19, 1, 18, 0.65, 4)
|
|
8
|
xB <- c(11176, 1.22, 31.4, 4.12, 9, 0.23, 1, 7 , 0.57, 5)
|
|
9
|
xC <- c(12089, 1.26, 34.1, 3.45, 4, 0.29, 0, 15, 0.38, 3)
|
|
10
|
# Задаются граничные значения характеристик
|
|
11
|
xmin <- c(8544, 1.17, 24.8, 3.45, 4, 0.19, 0, 7, 0.38, 3)
|
|
12
|
xmax <- c(12089, 1.26, 34.1, 4.73, 9, 0.29, 1, 18, 0.65, 5)
|
|
13
|
# Указывается, как характеристика влияет на качество объекта
|
|
14
|
# "TRUE" - чем больше значение, тем выше качество, "FALSE" - наоборот
|
|
15
|
inc <- c(TRUE, TRUE, TRUE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE)
|
|
16
|
# На основе значений характеристик рассчитываются значения отдельных показателей q1, ... qn
|
|
17
|
qA[inc]=(xA[inc]-xmin[inc])/(xmax[inc]-xmin[inc])
|
|
18
|
qA[!inc]=(xmax[!inc]-xA[!inc])/(xmax[!inc]-xmin[!inc])
|
|
19
|
qB[inc]=(xB[inc]-xmin[inc])/(xmax[inc]-xmin[inc])
|
|
20
|
qB[!inc]=(xmax[!inc]-xB[!inc])/(xmax[!inc]-xmin[!inc])
|
|
21
|
qC[inc]=(xC[inc]-xmin[inc])/(xmax[inc]-xmin[inc])
|
|
22
|
qC[!inc]=(xmax[!inc]-xC[!inc])/(xmax[!inc]-xmin[!inc])
|
|
23
|
# Задаются исходные данные для формирования множества возможных весовых векторов
|
|
24
|
k <- 50
|
|
25
|
h <- 1/k
|
|
26
|
# формируется множество всех возможных весовых векторов
|
|
27
|
# векторы с 2-мя компонентами
|
|
28
|
weight1 <- seq(0, k, by=1)
|
|
29
|
weight2 <- k-weight1
|
|
30
|
# векторы с 3-мя компонентами
|
|
31
|
f1 <- weight1
|
|
32
|
f2 <- weight2
|
|
33
|
for(i in 1:k){
|
|
34
|
restr <- logical()
|
|
35
|
f1 <- f1-1
|
|
36
|
restr <- (f1>-1)
|
|
37
|
weight1 <- c(weight1, f1[restr])
|
|
38
|
weight2 <- c(weight2, f2[restr])
|
|
39
|
}
|
|
40
|
weight3 <- k-weight1-weight2
|
|
41
|
# векторы с 4-мя компонентами
|
|
42
|
f1 <- weight1
|
|
43
|
f2 <- weight2
|
|
44
|
f3 <- weight3
|
|
45
|
for(i in 1:k){
|
|
46
|
restr <- logical()
|
|
47
|
f1 <- f1-1
|
|
48
|
restr <- (f1>-1)
|
|
49
|
weight1 <- c(weight1, f1[restr])
|
|
50
|
weight2 <- c(weight2, f2[restr])
|
|
51
|
weight3 <- c(weight3, f3[restr])
|
|
52
|
}
|
|
53
|
weight4 <- k-weight1-weight2-weight3
|
|
54
|
# Процедура добавления новых компонент (5-й, 6-й и т.д.) может быть продолжена.
|
|
55
|
weight1 <- weight1/k
|
|
56
|
weight2 <- weight2/k
|
|
57
|
weight3 <- weight3/k
|
|
58
|
weight4 <- weight4/k
|
|
59
|
# Задаются ограничения I1, I2, I3, Ig для 4-x групп весовых коэффициентов
|
|
60
|
# Формируются множества WD(I1), WD(I2), WD(I3), WD(Ig) допустимых векторов весовых коэффициентов
|
|
61
|
# Рассчитываются количества N(I1), N(I2), N(I3), N(Ig) элементов в множествах
|
|
62
|
Restrictions1 <- (weight1 > weight3+(1/(k*10))) & (weight3 > weight2+(1/(k*10))) & (weight2 > weight4+(1/(k*10))) & (weight4 >= 0.1-(1/(k*10)))
|
|
63
|
w11 <- weight1[Restrictions1]; w12 <- weight2[Restrictions1]; w13 <- weight3[Restrictions1]; w14 <- weight4[Restrictions1]
|
|
64
|
N1 <- length(w11)
|
|
65
|
Restrictions2 <- (weight3 > weight2+(1/(k*10))) & (weight2 > weight1+(1/(k*10))) & (weight1 >= 0.1 -(1/(k*10))) & (weight4 == 0)
|
|
66
|
w21 <- weight1[Restrictions2]; w22 <- weight2[Restrictions2]; w23 <- weight3[Restrictions2]
|
|
67
|
N2 <- length(w21)
|
|
68
|
Restrictions3 <- (weight2 > weight1+(1/(k*10))) & (weight1 > weight3+(1/(k*10))) & (weight3 >= 0.1 -(1/(k*10))) & (weight4 == 0)
|
|
69
|
w31 <- weight1[Restrictions3]; w32 <- weight2[Restrictions3]; w33 <- weight3[Restrictions3]
|
|
70
|
N3 <- length(w31)
|
|
71
|
RestrictionsG <- (weight1 > weight2+(1/(k*10))) & (weight2 > weight3+(1/(k*10))) & (weight3 >= 0.1 -(1/(k*10))) & (weight4 == 0)
|
|
72
|
wg1 <- weight1[RestrictionsG]; wg2 <- weight2[RestrictionsG]; wg3 <- weight3[RestrictionsG]
|
|
73
|
Ng <- length(wg1)
|
|
74
|
# Задается размер выборки
|
|
75
|
Nsample <- 10000000
|
|
76
|
# Случайным образом выбираются элементы (их номера) из множеств допустимых векторов
|
|
77
|
num1 <- sample(1:N1, size=Nsample, replace=TRUE, prob=NULL)
|
|
78
|
num2 <- sample(1:N2, size=Nsample, replace=TRUE, prob=NULL)
|
|
79
|
num3 <- sample(1:N3, size=Nsample, replace=TRUE, prob=NULL)
|
|
80
|
numg <- sample(1:Ng, size=Nsample, replace=TRUE, prob=NULL)
|
|
81
|
# Расчет выборочных значений сводных показателей
|
|
82
|
Q1A <- w11[num1]*qA["NPV"]+w12[num1]*qA["PI"]+w13[num1]*qA["IRR"]+w14[num1]*qA["DPP"]
|
|
83
|
Q2A <- w21[num2]*qA["Tproj"]+w22[num2]*qA["Prob"]+w23[num2]*qA["Opt"]
|
|
84
|
Q3A <- w31[num3]*qA["Tcomp"]+w32[num3]*qA["Share"]+w33[num3]*qA["Exp"]
|
|
85
|
QgA <- wg1[numg]*Q1A +wg2[numg]*Q2A +wg3[numg]*Q3A
|
|
86
|
Q1B <- w11[num1]*qB["NPV"]+w12[num1]*qB["PI"]+w13[num1]*qB["IRR"]+w14[num1]*qB["DPP"]
|
|
87
|
Q2B <- w21[num2]*qB["Tproj"]+w22[num2]*qB["Prob"]+w23[num2]*qB["Opt"]
|
|
88
|
Q3B <- w31[num3]*qB["Tcomp"]+w32[num3]*qB["Share"]+w33[num3]*qB["Exp"]
|
|
89
|
QgB <- wg1[numg]*Q1B +wg2[numg]*Q2B +wg3[numg]*Q3B
|
|
90
|
Q1C <- w11[num1]*qC["NPV"]+w12[num1]*qC["PI"]+w13[num1]*qC["IRR"]+w14[num1]*qC["DPP"]
|
|
91
|
Q2C <- w21[num2]*qC["Tproj"]+w22[num2]*qC["Prob"]+w23[num2]*qC["Opt"]
|
|
92
|
Q3C <- w31[num3]*qC["Tcomp"]+w32[num3]*qC["Share"]+w33[num3]*qC["Exp"]
|
|
93
|
QgC <- wg1[numg]*Q1C +wg2[numg]*Q2C +wg3[numg]*Q3C
|
|
94
|
# Расчет вероятностей попарного и абсолютного доминирования
|
|
95
|
pAB <- length(QgA[(QgA>=QgB)])/Nsample; pAC <- length(QgA[(QgA>=QgC)])/Nsample
|
|
96
|
pA <- length(QgA[(QgA>=QgB)&(QgA>=QgC)])/Nsample
|
|
97
|
pBA <- length(QgB[(QgB>=QgA)])/Nsample; pBC <- length(QgB[(QgB>=QgC)])/Nsample
|
|
98
|
pB <- length(QgB[(QgB>=QgA)&(QgB>=QgC)])/Nsample
|
|
99
|
pCA <- length(QgC[(QgC>=QgA)])/Nsample; pCB <- length(QgC[(QgC>=QgB)])/Nsample
|
|
100
|
pC <- length(QgC[(QgC>=QgA)&(QgC>=QgB)])/Nsample
|
|
101
|
# Оценки и доверительные интервалы сводных показателей
|
|
102
|
Q <- QgA
|
|
103
|
# Уровень значимости
|
|
104
|
a <- 0.05
|
|
105
|
Qmin <- mean(Q)-sqrt(1/(4*Nsample*a))
|
|
106
|
Qmax <- mean(Q)+sqrt(1/(4*Nsample*a))
|
|
107
|
print(c("Q=", mean(Q), "доверительный интервал:", Qmin, Qmax))
|
|
108
|
# Оценки и доверительные интервалы вероятностей доминирования
|
|
109
|
p <- pA
|
|
110
|
# Уровень значимости
|
|
111
|
a <- 0.05
|
|
112
|
pmin <- p+qnorm(a/2)*sqrt(p*(1-p)/Nsample)
|
|
113
|
pmax <- p+qnorm(1-a/2)*sqrt(p*(1-p)/Nsample)
|
|
114
|
print(c("p=", p, "доверительный интервал:", pmin, pmax))
|
References
1. Borzenkova A.A., Kolodko D.V. Postroenie svodnoi otsenki stoimosti ob''ektov intellektual'noi sobstvennosti // Upravlenie ekonomicheskimi sistemami: elektronnyi nauchnyi zhurnal. – 2017. – №11 (105). – s.42. URL: http://uecs.ru/index.php?option=com_flexicontent&view=items&id=4638:2017-11-14-09-37-11
2. Breili R., Maiers S. Printsipy korporativnykh finansov. – M.: ZAO «Olimp-Biznes», 2015. – 1008 s.
3. Van Khorn D., Vakhovich D. Osnovy finansovogo menedzhmenta. – M.: «I.D. Vil'yams», 2010. – 1232 s.
4. Esipov V.E. Kommercheskaya otsenka investitsii. – M.: KNORUS, 2014. – 698 s.
5. Zhuk S. N. Otsenka effektivnosti funktsionirovaniya slozhnykh sistem po ierarkhicheskoi sisteme pokazatelei // Tr. SPIIRAN, 26 (2013), S. 194–203.
6. Kobzar' A.I. Prikladnaya matematicheskaya statistika. Dlya inzhenerov i nauchnykh rabotnikov.-M.: FIZMATLIT, 2012. – 816 s.
7. Kolesov D.N., Kolodko D.V., Khovanov N.V. Baiesovskaya otsenka raspredeleniya znachenii finansovo-ekonomicheskikh pokazatelei: teoriya i vozmozhnye primeneniya // Primenenie matematiki v ekonomike. Sbornik statei. Vypusk 19. SPb.: Nestor-Istoriya, 2012. S. 107–127.
8. Kolesov D.N., Mikhailov M.V., Khovanov N.V. Otsenivanie slozhnykh finansovo-ekonomicheskikh ob''ektov s ispol'zovaniem sistemy podderzhki prinyatiya reshenii ASPID-3W. – Izd-vo SPbGU, 2004. – 63 s.
9. Kolodko D.V. Mnogokriterial'nyi vybor investitsionnogo proekta s pomoshch'yu metoda randomizirovannykh svodnykh pokazatelei // Upravlenie ekonomicheskimi sistemami: elektronnyi nauchnyi zhurnal. – 2019. – №3 (121). – s.11. URL: http://uecs.ru/instrumentalnii-metody-ekonomiki/item/5423-2019-03-16-08-01-31
10. Lipchanskaya, K. Yu., Baigulova, O. V. Algoritm otsenki finansovoi ustoichivosti kompanii pri opredelenii ee investitsionnoi privlekatel'nosti // Nauka i obrazovanie: khozyaistvo i ekonomika; predprinimatel'stvo; pravo i upravlenie. – 2019. – № 1. – S. 41-45.
11. Lobanova T. M., Livinskaya V. A. Kompleksnaya otsenka privlekatel'nosti investitsionnykh predlozhenii // Vestnik Belorussko-Rossiiskogo universiteta. – 2019. – №1 – s.115-121.
12. Nogin V.D. Lineinaya svertka kriteriev v mnogokriterial'noi optimizatsii // Iskusstvennyi intellekt i prinyatie reshenii. – 2014. – №4. S.73–82.
13. Rybkina E.A. Investitsionnaya privlekatel'nost' proekta: sushchnost' i podkhody k otsenke // Vestnik PNIPU. Sotsial'no-ekonomicheskie nauki. –2016. – S. 269-281.
14. Khovanov N.V. Analiz i sintez pokazatelei pri informatsionnom defitsite. – SPb.: Izdatel'stvo S.-Peterburgskogo universiteta, 1996. – 196 s.
15. Shiryaev A.N. Veroyatnost': Kn. 1. – M.: MTsNMO, 2017. – 552 s.
16. Mortey E.M., Ofosu E.A., Kolodko D.V., Kabobah A.T. Sustainability Assessment of the Bui Hydropower System // Environments. 2017. V. 4. Iss 2. 25 p. DOI: 10.3390/environments4020025
17. Hovanov N., Yudaeva M., Hovanov K. Multicriteria estimation of probabilities on basis of expert non-numeric, non-exact and non-complete knowledge // European Journal of Operational Research. 2009. Vol. 195. Issue 3. P. 857–863.
Link to this article
You can simply select and copy link from below text field.
|






