MAIN PAGE
> Back to contents
Modern Education
Reference:
Lialin A.V.
Tasks on the topic «Artificial Intelligence» in School Informatics
// Modern Education.
2022. № 4.
P. 43-49.
DOI: 10.25136/2409-8736.2022.4.39551 EDN: IPGOTT URL: https://en.nbpublish.com/library_read_article.php?id=39551
Tasks on the topic «Artificial Intelligence» in School Informatics
Lialin Andrei Vasilevich
Senior Lecturer of Applied Mathematics and Computer Science Department,
Vyatka State University
610000, Russia, Kirov region, Kirov, Moskovskaya str., 36

|
lialinandrei@rambler.ru
|
|
 |
|
DOI: 10.25136/2409-8736.2022.4.39551
EDN: IPGOTT
Received:
24-12-2022
Published:
31-12-2022
Abstract:
Artificial intelligence is a branch of computer science in which programs are written and devices are created that imitate the intellectual functions of a person. These programs and devices are used in a variety of areas, such as technology, science, art, games, medicine, commerce, finance, education. If the disciplines with the names «Fundamentals of Artificial Intelligence», «Intelligent Information Systems», «Data Mining» and «Machine Learning» are already included in the standards of higher education, then artificial intelligence is not considered at school, neither at the theoretical level, nor at the practical level. Therefore, the subject of this research is the content of the topic «Artificial Intelligence» in the school course of computer science. As a result of a theoretical analysis of school and university educational standards and teaching aids, as well as observation of learning, a positive answer was received to the question of the possibility of studying the topic «Artificial Intelligence» in the school course of computer science. It turned out that from this complex topic, you can choose tasks that, after simplification and adaptation, will be interesting and accessible to schoolchildren. In the article, for example, four such tasks are given, namely, clustering, classification, recognition and control. Their solution allows not only to introduce students to a new and promising area of informatics, but also brings learning closer to the activities of a scientist, and therefore develops their intelligence.
Keywords:
school informatics, artificial intelligence, word tasks, motivation, scientific method, development of intelligence, clustering, classification, recognition, training neural networks
This article is automatically translated.
You can find original text of the article here.
IntroductionArtificial intelligence is one of the most promising areas of computer science. Here they create programs that recognize text and speech, translate from one language to another, identify plagiarism, recommend movies, books or music, search for information on the Internet, control robots, predict stock prices, prove theorems, play chess, make a medical diagnosis, and so on and so forth. And in a few words, here they study "how to make computers do things that people are currently doing better" [1, p.3]. Intelligent systems are a mandatory and fundamental area in the recommendations for teaching computer science compiled by the joint Commission of the ACM and IEEE Computer Science [2]. They teach students of many American and European higher educational institutions. However, in Russian school textbooks on computer science, the topic of artificial intelligence has been touched upon for a long time and only twice. This is a textbook by V. A. Kaimin in 1989 [3] and a textbook by I. G. Semakin in 1998 [4]. Both provide a general overview and talk about the Prolog programming language. Currently, except for the only elective course of L. N. Yasnitsky [5], issues related to artificial intelligence are not considered in general computer science. Although they could become a source of real, meaningful, natural, feasible and interesting tasks for schoolchildren. Their examples are given below. Example 1. ClusteringClustering is the division of objects into groups. Each group should consist of similar objects, and objects from different groups differ significantly. Clustering is used, for example, in recommendation systems. Users are divided into groups and everyone is recommended those products, movies, music, books that his "classmates" buy, watch, listen to, read. Let's say the ratings of several users for two films are known (Fig. 1). The figure shows that they can easily be divided into three groups. 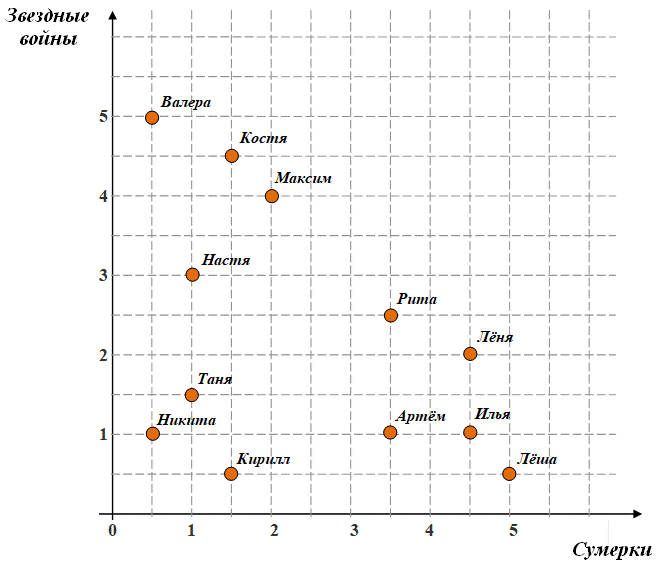
Figure 1. User ratings for two films. Of course, when there are more users and movies, there is no visual splitting to do. For this, many clustering algorithms have been invented. For example, a clustering algorithm using a minimal spanning tree. We build a minimal spanning tree on the points. Let them be divided into k clusters. Then we remove (k-1) of the longest edges from the tree. It splits into exactly k subtrees, which will be clusters. Task1. Define the minimum spanning tree. You must understand all the words that are found in the definitions. 2. Formulate the well-known Kruskal algorithm for constructing a minimal spanning tree. 3. Perform the Kruskal algorithm manually for the points from the figure. Namely, draw all the edges and indicate in what order they appeared. Remove the two longest edges from the resulting tree. Users will be divided into three groups. Example 2. ClassificationClassification is the assignment of a new object to one of these classes.
One of the simplest classification algorithms is called the k nearest neighbors algorithm. For example, we want to build a system that decides whether to give a person a loan or not, whether he belongs to the class of "good" or to the class of "bad" customers. We know the history of the bank (Fig. 2). Customers marked with green circles have returned money in the past, and red ones have not returned it. 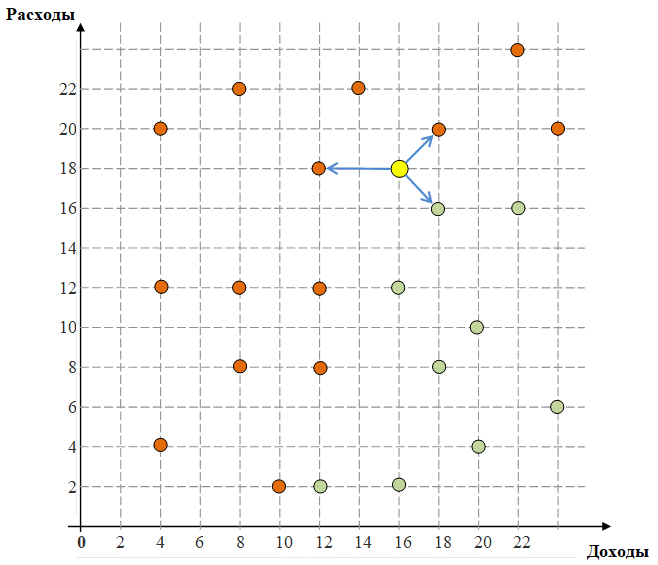
Figure 2. The history of the bank. A new client arrives – a yellow circle. What should I do with it? We find k of its nearest neighbors. Let k=3. If there are more green ones among them, then we approve the loan, and if there are more red ones, we refuse. Of course, real systems include thousands of customers and look not only at their expenses and income. Task1. Let the new client have an income of 14, and an expense of 2. In the algorithm of k nearest neighbors, the parameter k=5. What answer will the algorithm give for this client and why? 2. Why is it better to take the parameter k odd? 3. The user enters the client's income and expense. The program, using the algorithm of k nearest neighbors at k = 3, tells whether to give him a loan or not. Solve the problem in MS Excel. Take the data from the drawing. Save them on a sheet.
Example 3. Recognition A "picture" of black and white cells is stored in a text file (Fig. 3). Black cells are designated 1. White cells are 0. We read it into a two–dimensional array. 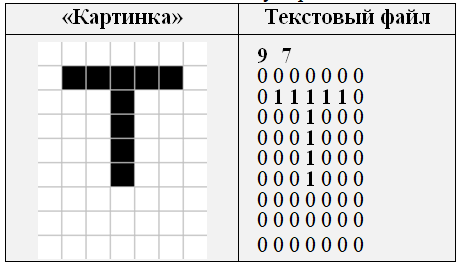
Figure 3. An example of a "picture" and a text file for it. TaskOn the "picture" there is a figure. Come up with an algorithm and write a program that recognizes exactly which digit it is. Both their size and location can be any. But they are drawn only in vertical and horizontal solid segments with a thickness of one cell (Fig. 4). 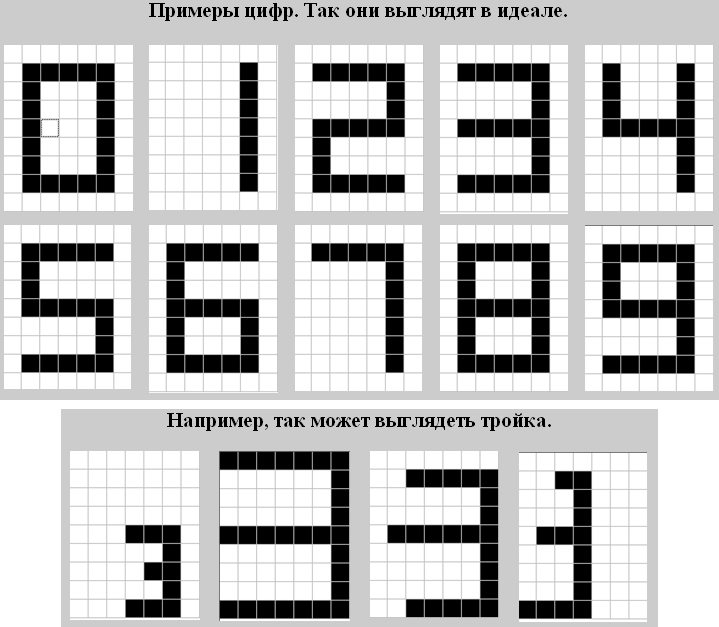
Figure 4. Examples of writing numbers. Example 4. ManagementLet the bully have three detectors. The force detector is triggered if a passerby can protect himself. People detector – if there is someone else on the street besides a passerby. Money detector – if you run out of money. The detector that triggered gives out a signal 1. Otherwise - 0. A bully attacks a passerby if he cannot defend himself, there is no one around and the money has run out. In other cases, he just watches. TaskBuild and train "manually" a neural network that will control such behavior of a bully. There are three detectors at its entrance. There is one command signal at the output. It is equal to 1 if the bully attacks, and 0 if not. Hint. Here it is enough to take a neural network consisting of only one layer and one neuron. ConclusionsThe non-text problem has already been formulated in the language of the field of knowledge by which it can be solved, and the text problem requires the translation of its conditions into this language [6, p. 10]. For example, the following problem from a school textbook on computer science under the authorship of K.Y. Polyakov and E.A. Eremin is non-textual. "Fill the array with random numbers in the range 20..100 and count separately the number of elements with even and odd values" [7, p.170]. In his work [8], the Polish teacher V. Okon voiced and justified the following thesis. The more successful education is and the more intelligence develops, the more the student gets on the path that the scientist follows in the course of research (Fig.5). 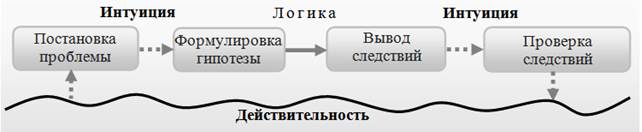
Figure 5. The full cycle of scientific knowledge What happens if students are offered only non-text tasks?They will be turned off from the very first, important and interesting step on this path. They will not have "the conditions and opportunities to learn to pose problems and formulate special questions themselves – there is a clear deficiency in the development of a thinking culture" [9]. The above tasks from the field of artificial intelligence are just textual. In addition to getting acquainted with the "inner kitchen" of artificial intelligence, they bring learning closer to the activity of a scientist, which means they contribute to the intellectual development of students.
References
1. Gavrilov A. V. Systems of artificial intelligence / A. V. Gavrilov. – Novosibirsk: Publishing house of NSTU, 2001. – 67 p.
2. Computing Curricula Computer Science 2013. URL: https://www.acm.org/binaries/content/assets/education/cs2013_web_final.pdf (accessed 12/29/2022).
3. Kaymin V. A. Fundamentals of informatics and computer technology. Textbook for grades 10-11 / V. A. Kaymin, A. G. Shchegolev, E. A. Erokhina, D. P. Fedyushin. – M.: Enlightenment, 1989. – 272 p.
4. Semakin I.G. Computer science. Basic course textbook (grades 7-9) / I. G. Semakin, L. A. Zalogova, S. V. Rusakov, L. V. Shestakova – M .: Basic Knowledge Laboratory, 1998. – 464 p.
5. Yasnitsky L. N. Artificial intelligence. Elective course / L. N. Yasnitsky. – M.: BINOM. Knowledge Laboratory, 2011. – 240c.
6. Fridman L.M. Fundamentals of problemology / L.M. Friedman. – M.: Sinteg, 2001. – 228 p.
7. Polyakov K. Yu. Informatics. Grade 10. Part 2 / K. Yu. Polyakov, E. A. Eremin. – M.: Binom. Knowledge Laboratory, 2015. – 304 p.
8. Okon V. Fundamentals of problem-based learning / V. Okon. – M.: Enlightenment, 1968. – 208 p.
9. Yulov V. F. Thinking in the context of consciousness / V. F. Yulov. – M.: Academic project, 2003. – 496 p.
Link to this article
You can simply select and copy link from below text field.
|





