|
MAIN PAGE
> Back to contents
Litera
Reference:
Freidson O.A., Verezubova E.E.
Corpus methods in research and study/teaching of the French language.
// Litera.
2023. № 2.
P. 22-33.
DOI: 10.25136/2409-8698.2023.2.37471 EDN: HEEJBN URL: https://en.nbpublish.com/library_read_article.php?id=37471
Corpus methods in research and study/teaching of the French language.
Freidson Ol'ga Aleksandrovna
ORCID: 0000-0002-1933-492X
PhD in Philology
Olga A. Freidson, Associate Professor, Romano-Germanic Philology and Translation Departement, Saint Petersburg State University of Economics
191023, Russia, Saint Petersburg, Sadovaya str., 21

|
olga-freidson@mail.ru
|
|
 |
|
Verezubova Ekaterina Evgen'evna
ORCID: 0000-0003-4915-7992
PhD in Philology
Ekaterina E. Verezubova, Associate Professor, Romano-Germanic Philology and Translation Departement, Saint Petersburg State University of Economics
191023, Russia, Saint Petersburg, Sadovaya str., 21
|
|
c_verezubova@mail.ru
|
|
|
|
DOI: 10.25136/2409-8698.2023.2.37471
EDN: HEEJBN
Received:
03-02-2022
Published:
12-02-2023
Abstract:
The aim of the work is to identify the possibilities and specifics of using corpus methods in conducting research on the material of the French language and in teaching French. The growing interest in the methods of corpus research based on specific language data and the insufficient development of the issue on the material of the French language determine the relevance of the work. The analysis has shown that today there are various resources for conducting corpus research on the material of the French language, including literary text corpora, parallel corpora, oral speech corpora, which create a specially organized multidimensional infrastructure of the language space, giving a comprehensive idea of language units, their compatibility, semantics and functions. The authors have demonstrated that the existing corpus managers can be successfully applied in teaching French at the initial level, from the very beginning forming important linguistic and methodological competencies among linguist students. The scientific novelty of the research consists in a comprehensive review of the existing French corpus resources and the possibilities of their use in research and in teaching French. The results of the study can be used both for further development of research in the field of history, grammar, lexicology, stylistics of the French language based on corpora, and for the development of tasks for teaching French using corpus data, which is of practical significance of the study.
Keywords:
corpus, linguistics, teaching methods, French, concordance, collocation, corpus manager, lexical meaning, annotation, communicative competence
This article is automatically translated.
You can find original text of the article here.
IntroductionWith the advent of corpus linguistics, a radical change took place in the relationship between language and speech. According to V.A. Plungyan, there is a "... change of theoretical priorities with the transition from "system" to "usage", from "language" to "speech" [1, p. 7]: thanks to the possibility of collecting and processing a large amount of data using new technologies, speech, both written and oral, becomes available for large-scale analysis. At the center of the study is the discursive practice itself, which A. Kamber and M. Dubois rightly consider to be the only truly scientific and trustworthy way to the language system [2] (our translation). Corpora and concordances created on their basis become "ideal tools" that allow us to observe and study the connections between forms and contents that are accepted in a certain language community [3] (our translation). The use of a large amount of language data, the ability to instantly trace a language phenomenon on a large number of examples, the statistical visibility of data [4, p. 187] leads to a qualitatively different view of dictionaries, grammars and foreign language teaching itself. K.P. Chilingaryan emphasizes: "... the corpus nature of dictionaries and grammars increases their reliability, reliability and objectivity" [5, 196]. The idea of corpus and concordance is initially connected with the contextualization theory of John Rupert Firth, a British scientist of the mid-20th century, according to which, in order to establish the meaning of a form, it is necessary to put it in context, while the elements immediately preceding or following this form acquire particular importance [6, pp. 42-43]. Contextualization at the lexical level is called "collocation", a typical and permanent environment of a language form, its usual "company" [6, p. 43]. The study of syntagmatic connections based on text corpora is widely used in the modern works of Y.V. Bogoyavlenskaya [7], E.M. Khiminets [8], Z.B. Dolgikh [9] and others. Moreover, today the entire "language-speech" space is thought of as a continuum, which is characterized by interpenetration and interaction of levels, where, as M. V. Kopotev notes, instead of "modeling the rules of interaction of language units divided into levels", a description of "usage parameters" is proposed [10, 100], i.e. the border as between language levels, so between the division "language-speech" becomes extremely conditional. Recent studies indicate that corpus methods are actively used in the study of both language research and for special purposes (L.R. Komalova [11] considers the creation of medical vocabulary corpora, M.A. Kazharova studies general issues of the creation of terminological corpora), and in general in the study of a foreign language, helping to overcome the interference of the native language and developing a research interest in learning a foreign language. The works of A.E. Cherenda [13], O.G. Gorina [4], K.P. Chilingaryan [5], I. A. Kotyurova [14] are devoted to these issues. Corpus studies, originating in the English–speaking linguistic environment, today cover more and more languages: Y.V. Bogoyavlenskaya [15] studies the issues of corpus linguistics on the example of English, French and Russian languages, I.A. Kotyurova [14] - German, Z.B. Dolgikh [9] on the material of Portuguese, etc. This became possible not only due to the creation of both monolingual and parallel corpora (for example, the National Corpus of the Russian Language is constantly expanding the database of parallel corpora) [16], but also thanks to corpus managers who allow you to work with independently selected and placed in them arrays of data in various languages, for example, Sketch Engine [17], AntConc [18]. MethodologyThe purpose of the article is to review the corpus resources presented by the research centers of the French language, and to demonstrate the possibilities of corpus methods in research and in the study of the French language. Moreover, "research" and "study" in the light of corpus methods seem to us as a single whole, since their use implies "discoveries" made by the student, his own reflections on examples and conclusions about the use. The work is based primarily on the methods of linguistic and semantic analysis using the SketchEngin corpus manager. Let's briefly describe the methodology of working with this service. SketchEngine allows you to perform a keyword search, the results of which it presents in the form of a concordance (a list of all the uses of the searched words). This representation of data makes it possible to observe data in two dimensions: vertical, which corresponds to the paradigmatic axis, and horizontal, corresponding to the syntagmatic axis. The vertical axis represents the totality of occurrences of a keyword in the corpus, namely, the totality of possible uses of this word in the language, its paradigmatic dimension. Therefore, the corpus, if viewed along the vertical axis, becomes an expression of the language. For example, a search for the beaucoup lexeme gives us a list of concordances, after studying which we can get a complete picture of the ambiguity of this lexeme (the structure of the lexical meaning is taken from the dictionary entry of the explanatory dictionary Petit Robert [19]): 1. Before the noun beaucoup acts as a quantitative word (un grand nombre de, une grande quantit? de) - lines 1, 7, 8, 10, 14. 2. in the nominative function of the subject (de nombreuses choses, personnes) – lines 9, 11. 3. as an intensifier of the verb action – lines 5, 13. 4. as an element of the degree of comparison – lines 2, 3, 6, 12. 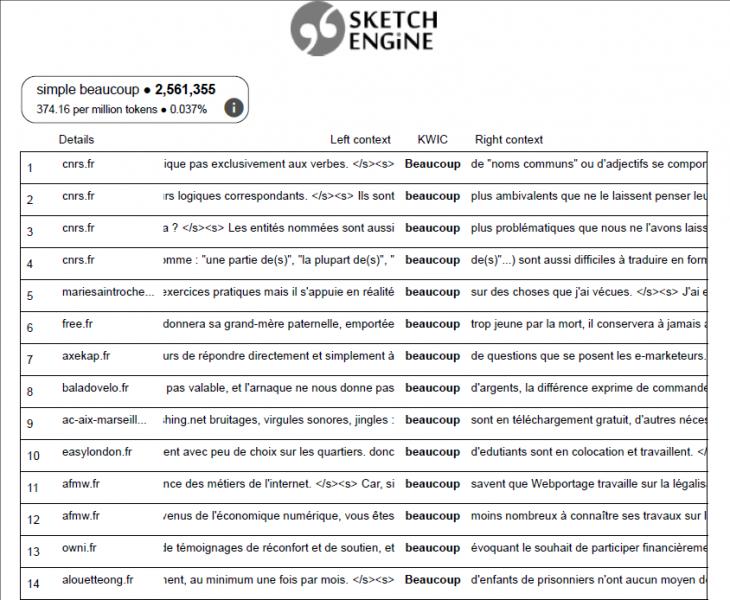
Fig. 1 – beaucoup search concordances in Sketch Engine
The horizontal axis, on the contrary, represents the use of a keyword in a specific and specific linguistic context, so we are at the syntagmatic level: each concordance corresponds to a separate act of speech. For example, we present the full context of the use of the beaucoup lexeme in the 8th concordance: Aucune promesse n'est pas valable, et l'arnaque ne nous donne pas beaucoup d'argents, la diff?rence exprime de commander le payant pour une utilisation accostable, nonobstant, un calcul de From the point of view of the didactics of the French language, it is important that students (both elementary and advanced level) learn to observe both axes, since it is the study of these two dimensions that will give them the opportunity to discover patterns that will allow them to systematize and learn the rules of using the language. But it is quite obvious that the type and degree of complexity of tasks will vary depending on the level of students. ResultsCorpus resources of the French language: a brief overview. French researchers are actively engaged in the creation and processing of corpus resources, both for written [20] and oral speech [21]. The first French corpus of oral speech can be considered the "Archives de la parole" (Archives of speech), collected by Ferdinand Brunot [22], professor at the University of Paris, in 1911-1914 and reflecting the peculiarities of oral speech in representatives of various social strata living in different regions of France and, accordingly, speaking different dialects. Today there are many oral speech corpora, which, on the one hand, as H. Tyne emphasizes, are designed to preserve the "linguistic heritage" [23], on the other hand, are effectively used in language learning and, in particular, language for special purposes [24]. As for written resources, for several decades French lexicography has been trying to prove that dictionaries are not "museums" of words, offering new types of dictionaries and new ways of using them, in particular, when searching for collocations [25]. As noted by C. Fabre and M. Lecolle, this makes it possible to create a kind of continuum between dictionaries and text corpora [26]. In this sense, both the Frantext corpus [27], which was originally created as a source of language material for the Tr?sor de la langue fran?aise dictionary from 1971 to 1994, and the TLF dictionary itself, which contains as many as 16 volumes in paper form, but has long existed in the electronic version of TLFi created by the Center, deserve special attention. analysis and computer processing of the French language [28]. It is the electronic and online version of this dictionary that convincingly demonstrates a smooth transition from the dictionary to the corpus, because, thanks to special search functions, it allows not only to view extensive dictionary entries, but also to search for word usage or collocations in all dictionary articles. With the completion of the TLF dictionary, the Frantext text corpus continued its independent existence and development. Today it is a paid resource that includes more than 4,500 works in French, capturing an extensive layer of texts, starting with the "Song of Roland" and up to modern authors. The corpus is fully annotated and offers a wide range of research functionality (the ability to make a selection by epoch, author, genre). In addition, the corpus offers a kind of "infrastructure", thanks to the context menu, where for the word presented in the concordance, you can immediately see the definition and etymology in the available dictionaries. Thus, the French corpus resources follow the modern trend of creating a multidimensional infrastructure of the language space, which is valuable for the researcher and gives a comprehensive idea of language units, their compatibility, semantics and functions. In addition to the resources offered by French researchers, multilingual case managers can be successfully used both in research and in educational work, using the example of one of which (SketchEngine) we will demonstrate the possibilities of teaching French. SketchEngine is a universal tool for both the study of language processes and for learning/teaching a foreign language. This resource contains 500 ready-to-use corpora in more than 90 languages, each of which is based on Internet sources, representing the current state of the language, and has a size of up to 60 billion occurrences, which provides a representative, constantly replenished language sample. In addition, using this resource, the researcher can create his own corpus for his own purposes. We rely on the data of the French language corpus presented on the platform. The specifics of using concordance in the teaching methodology of learning French.In teaching a foreign language, an important goal is the formation of foreign language communicative competence. The more often a student encounters authentic speech, the more likely it is that his statement in a foreign language will correspond to the accepted usage. Language learning through direct observation of language data (data driven learning) was developed in the 90s of the last century. According to this approach, the starting point in language learning is a direct collision with language data provided by language users [30, 41]. That is, the more often a student meets exemplary models in the learning process, the faster and better the process of mastering a foreign language takes place. Since language corpora are a collection of authentic texts (written or oral) containing many exemplary language models, the use of corpus data in the process of teaching a foreign language allows you to master these models in a simple and fascinating manner. A concordance is a list of all cases of the use of the desired words in speech. Often this list is very large and requires preliminary processing by the teacher, especially if exercises based on it are intended for beginners. Too many cases and the complexity of contexts can cause great difficulties for students. Therefore, it is necessary to limit the search or filter and pre-select the best samples of language models to which students will have access.
For example, to formulate the rules for using nouns after quantitative words in French (for example, beaucoup de), the list of concordances compiled by searching for the beaucoup lemma (Fig. 1) is not representative, since all the meanings of this word fall into it, which causes certain difficulties for students. In order to eliminate all unnecessary examples from the list of concordances, the teacher first needs to search for keywords beaucoup de and apply the Good dictionary examples (GDEX) function in the Sketch Engine, which automatically selects the simplest and most illustrative examples. 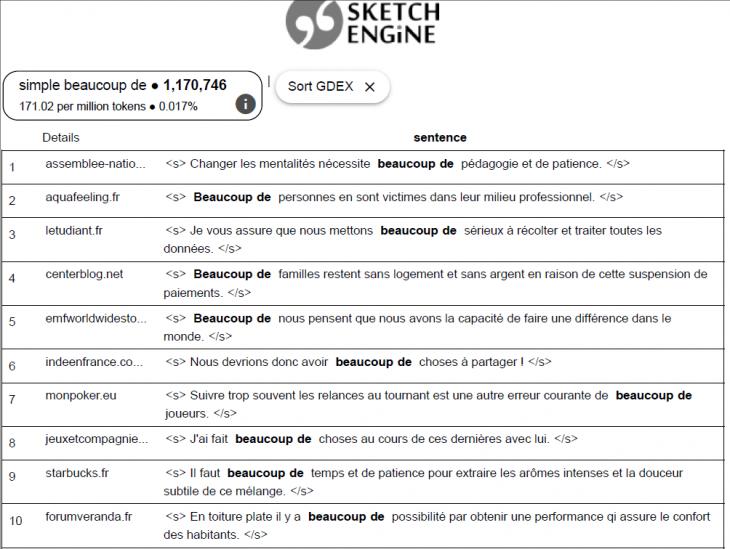
Fig. 2 – concordances for the beaucoup de search with the GDEX functionThus, depending on the level of students and on the set pedagogical task, the teacher should pre-filter the concordances. The use of corpora in the preparation of tasks for improving lexical skills.1. Identification of semantic differences of synonymous words. Thanks to the Word Sketch Difference function, the Sketch Engine manager allows you to conduct a comparative search and identify semantic differences between two lexemes. For example, the search results for the dire and parler lexemes show that the verb parler is more often used with such additions as langue, langage, as well as with the names of specific languages fran ? ais, anglais. While the verb dire for the most part has such additions as chose, merci, loi, contraire, v? rit ?. From this we can conclude that the equivalent of the verb parler can be the Russian verb to speak, and the equivalent of the verb dire – to say. Tasks of this type can easily be performed by elementary level students. 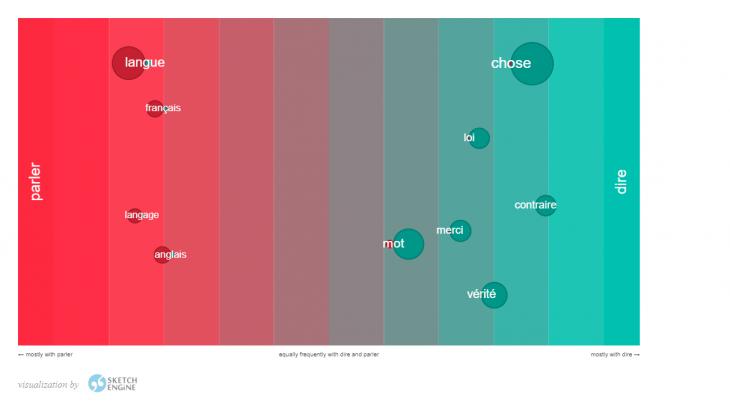
Fig. 3 – semantic difference between the verbs parler and dire.2. The use of a linguistic corpus for the study of phrases. Learning a foreign language is not only and not so much mechanical memorization of words. Language is primarily a combination of words. The British linguist J. Sinclair [29] noted that we all think in patterns, established phrases, and the knowledge of these correct, commonly used models in a particular linguistic society, the established combinations is precisely the most important factor in successful communication. It should be clarified that the study of collocations includes not only providing students with a selection of lexical opportunities to increase their vocabulary, but also familiarity with stable phrases. The Sketch Engine provides information about the compatibility of the words you are looking for, thanks to the Word Sketch function, and the Thesaurus function allows you to get lists of semantically related words. So, the Word Sketch search function for the word pied provides the following most frequent collocations of the type "verb + pied in the function of the object of action": lever – au pied lev?; mettre – mis les pieds; poser – poser le pied; laver – laver les pieds; repository – repose pieds; remettre – remettre les pieds; marcher – marcher pieds nus; tra?ner – tra?nant les pieds; garder – garder les pieds; joindre – ? pieds joins; casser – casser les pieds. Discussion.
As the analysis of the literature [7; 15] has shown, the functionality of French corpus resources is familiar to Russian linguists, but not widely enough. Thus, the review undertaken in our work allows us to popularize them among Russian colleagues. At the same time, recent works demonstrate the use of corpora for the search and analysis of specific linguistic phenomena in various languages, including French [7-9; 11; 14]. The article also identifies the principles and features of teaching French using the SketchEngine corpus, demonstrates specific ways to use the system's capabilities when distinguishing synonyms and studying collocations. The methods under study reflect the general current trend of overcoming interference and developing a research approach in teaching, which is actively used on the material of the English language [4; 5; 13], while only the first steps are being taken in teaching French in domestic research today. Conclusion.We have seen that today there are a wide variety of specially organized corpus resources that represent the French language as a multidimensional space and provide new opportunities both for its research and for its study/teaching. The enclosures allow you to access new data or hints for foreign language learners, observe oral markers, learn a live, spoken language even in the absence of direct contact with native speakers. We believe that the active use of corpus methods in teaching / learning a language will allow us to link theory with practice, derive rules for the use of language tools and maintain interest in the learning process.
References
1. Plungian, V.А. (2008). Корпус как инструмент и как идеология: О некоторых уроках современной корпусной лингвистики [Corpus as a Tool and as an Ideology: On Some Lessons of Modern Corpus Linguistics]. Russian Language and Linguistic Theory, № 2 (16), 7–20.
2. Kamber, A., & Dubois, M. (2016). Corpus, grammaire et francais langue etrangere : une concordance necessaire. Linguistik Online, Vol. 78, Issue 4, 2016, 3+. Retrieved from link.gale.com/apps/doc/A486694960/LitRC?u=anon~7963ab96&sid=googleScholar&xid=b7e41a56. (accessed 20.01.2022).
3. Di Vito, S. (2013). L’utilisation des corpus dans l’analyse linguistique et dans l’apprentissage du FLE [The use of corpora in linguistic analysis and in learning French as a foreign language]. Linx, No. 68-69, 159–176. Retrieved from https://journals.openedition.org/linx/1519 (accessed 10.01.2022).
4. Gorina, О. G. (2018). Corpus research tools in l2 teaching. Tomsk State University Journal, No. 435, 187 – 194. doi:10.17223/15617793/435/24
5. Chilingaryan, K.P. (2021). Corpus Linguistics: Theory Vs Methodilogy. RUDN Journal of Language Studies, Semiotics and Semantics, Vol. 12, No. 1, 196-218. doi:10.22363/2313-2299-2021-12-1-196-218
6. Luzina, L.G. (2001). Джон Руперт Фёст [John Rupert First]. Европейские лингвисты ХХ века, No. 2001, 35–50.
7. Bogojavlenskaja, Y.V. (2019). Парцеллографема и парцеллятная сетка: корпусное исследование [Parcellographeme and parcel mesh: a corpus study]. Eurasian Humanitarian Journal, No. 1, 4-10.
8. Khiminets, Е.М. (2021). Исследование структурно-семантических схем коллокаций лексемы «Mission» во французских газетах Libération и le Figaro [Research of structural-semantic schemes of collocations of the lexeme «Mission» in the French newspapers Libération and le Figaro], Eurasian Humanitarian Journal, No. 4, 37–47.
9. Dolguikh, Z.B. (2018). An overview of some basic possibilities of corpus in the field of linguistic research (on the example of the analysis of graduation means in the Portuguese language), Вестник Московского государственного лингвистического университета. Гуманитарные науки, No. 5 (795), 21–31.
10. Kopotev, M. V. (2021). Some houghts on Corpus and General Linguistics. Philological Class, Т. 26, No. 2, 90-102. doi:10.51762/1FK-2021-26-02-07
11. Komalova, L.R. (2020). Корпусные исследования в лингвистике применительно к медицинской практике [Corpus research in linguistics in relation to medical practice]. Социальные и гуманитарные науки. Отечественная и зарубежная литература. Серия 6: Языкознание. Реферативный журнал, No, 1, 115-122.
12. Kazharova, M.A. (2021). Corpus linguistics and specialized languages in lexicology and terminology. The world of science, culture, education, No. 12, 230-238.
13. Cherenda, А.E. (2020). Корпусная лингвистика и обучение через исследования [Corpus linguistics and learning through research]. Международный научный журнал «Вестник науки», No. 11 (32), Т.1, 28-34.
14. Koturova, I.А. (2020). Создание корпусов учебных текстов как развивающееся направление корпусной лингвистики [Creation of educational text corpora as a developing area of corpus linguistics]. The International scientific journal, No. 5, 100-108. doi:10.34286/1995-4638-2020-74-5-100-108
15. Bogoyavlenskaya, Y.V. (2017), Сопоставительный объектно-ориентированный корпус: определение понятия и принципы формирования [Comparative object-oriented corpus: definition of the concept and principles of formation]. Многоязычие в образовательном пространстве, No. 9, 3–12.
16. Russian National Corpus. Retrieved from https://ruscorpora.ru (accessed 12.01.2022).
17. SketchEngine. Retrieved from https://www.sketchengine.eu/ (дата обращения 20.12.2021).
18. Laurence Anthony's Website. AntConc Homepage. Retrieved from https://www.laurenceanthony.net/software/antconc/ (accessed 20.01.2022).
19. Le Robert Dico en ligne. Retrieved from https://dictionnaire.lerobert.com/ (accessed 14.01.2022).
20. Debaisieux, J.-M. (2013). Analyses lingustiques sur corpus : subordination et insubordination en français [Lingustic analyzes on corpus: subordination and insubordination in French]. Paris, Hermes Lavoisier.
21. Cordereux, P. (2016), Comment indexer les corpus oraux? [How to index oral corpora?]. Histoire Épistémologie Langage, No. 38/2, 101-113. Retrieved from https://www.persee.fr/doc/hel_0750-8069_2016_num_38_2_3564 (accessed 12.01.2022).
22. Brunot, F. Archive de la Parole [Archive of the Word.]. Retrieved from https://gallica.bnf.fr/html/und/enregistrements-sonores/archives-de-la-parole-ferdinand-brunot-1911-1914?mode=desktop (accessed 20.01.2022).
23. Tyne, H. (2009). Corpus oraux par et pour l’apprenant [Oral corpora by and for the learner]. Mélanges CRAPEL. Centre de recherches et d’applications pédagogiques en langues, No. 31, 91-111. Retrieved from https://hal.archives-ouvertes.fr/file/index/docid/416544/filename/TYNE_MELANGES.pdf (accessed 13.01.2022).
24. Bourhis, V., & Gagnon, R. (Eds.). (2020). Les corpus parlés et leur didactisation: quelle parole (ap)prise dans l'espace de la classe? [Spoken corpora and their didactization: what speech (learned) taken in the classroom space?]. Vol. 198, Paris, France: Didier Érudition Klincksieck.
25. Tutin, A. (2005). Le dictionnaire de collocations est-il indispensable? [Is the dictionary of collocations essential?]. Revue française de linguistique appliquée, Vol. X, No. 2, 31-48. https://doi.org/10.3917/rfla.102.48
26. Fabre, C., & Lecolle, M. (2009). S’approprier des instruments d’observation de la langue pour élaborer des recherches : le TLFi et Frantext pour des étudiants de linguistique [Appropriating language observation instruments to develop research: the TLFi and Frantext for linguistics students]. Pratiques, No. 143-144, 139-152. Retrieved from https://doi.org/10.4000/pratiques.1424 (accessed 03.02.2022).
27. Frantext. Retrieved from http://www.frantext.fr (accessed 10.01.2022).
28. Trésor de la Langue Française informatisé. Retrieved from http://atilf.atilf.fr/tlf.htm (accessed 20.01.2022).
29. Sinclair, J. (1996). The search for units of meaning. Textus, No. 9 (1), 75–106.
30. Auzéau, F., & Abiad L. (2018). The Corpus : An Inductive Tool for the Teaching and Learning of Grammar. Synergies France, No. 12, 175-187.
Peer Review
Peer reviewers' evaluations remain confidential and are not disclosed to the public. Only external reviews, authorized for publication by the article's author(s), are made public. Typically, these final reviews are conducted after the manuscript's revision. Adhering to our double-blind review policy, the reviewer's identity is kept confidential.
The list of publisher reviewers can be found here.
The peer-reviewed article "Corpus methods in research and study/teaching of the French language" undoubtedly examines the topical topic of Romance linguistics, as well as the demonstrated methodology of corpus research and discusses methodological aspects of linguodidactics. The author presents interesting material from a scientific point of view, which is of significant importance for the theory and practice of both Romance philology and corpus linguistics and the theory of teaching foreign languages. It should be noted that this work contributes to the study of not only corpus studies, but also draws the attention of linguists to the perhaps undeservedly neglected French language in the light of the "boom" in the study of Chinese and Spanish and global English. Globalization as an integral part of our lives, multiculturalism and multilingualism of the world's megacities encourage researchers to pay more and more attention to the problems of intercultural communication and methods of effective language teaching. The purpose of the article is to review the corpus resources provided by the French language research centers and demonstrate the possibilities of corpus methods in research and in learning French. The work is based primarily on the methods of linguistic and semantic analysis using the SketchEngin corpus manager. One of the aspects of the work is to demonstrate the experience of successful use of corpora in teaching at different stages of mastering the French language. The article is structured, consists of an introduction, the main part, a description of the research results and presentation of conclusions. The article presents a research methodology, the choice of which is quite adequate to the goals and objectives of the work. The study was carried out in line with modern linguistic approaches. Such works using various methodologies are relevant and, taking into account the actual material, allow us to replicate the principle of research proposed by the author on other linguistic material. The postulated by the author is illustrated by practical language material. It should be noted that the bibliography contains 30 items, among which both domestic and foreign sources are presented. We believe that for a comprehensive consideration of the issue under study, it would be important to refer to more fundamental scientific literature: monographs and dissertations. However, it is unclear whether the author violated the generally accepted principle of compiling a list of used literature in alphabetical order and separating works in Russian from foreign publications. Technical errors should also include a link to source 2 (not available). The article will undoubtedly be useful to a wide range of people, philologists, novelists, linguists, students, undergraduates and graduate students of specialized universities. In general, it should be noted that the article is written in scientific language, well structured, typos, spelling and syntactic errors, inaccuracies were not found. The overall impression after reading the reviewed article is positive, the work can be recommended for publication in a scientific journal from the list of the Higher Attestation Commission.
Link to this article
You can simply select and copy link from below text field.
|
|





